Embodied Scenarios#
This category includes embodied training examples with SOTA models (e.g., pi0, pi0.5, OpenVLA-OFT) and different benchmarks (e.g., LIBERO, ManiSkill, RoboTwin, MetaWorld), as well as reinforcement learning training examples on real robots.
RL with ManiSkill Benchmark
ManiSkill + OpenVLA + PPO/GRPO achieves SOTA performance

RL with LIBERO Benchmark
LIBERO + OpenVLA-OFT + GRPO reaches 99% success rate
RL on π₀ and π₀.₅ Models
Significant improvement in RL training on π₀ and π₀.₅

RL with Behavior Benchmark
Support Behavior+OpenVLA-OFT+PPO/GRPO training

RL with MetaWorld Benchmark
Support MetaWorld+π₀/π₀.₅+PPO/GRPO training

RL with IsaacLab Benchmark
Support IsaacLab+gr00t+PPO training

RL on GR00T-N1.5 Model
Support GR00T-N1.5 RL fine-tuning.

RL with CALVIN Benchmark
Support CALVIN+π₀/π₀.₅+PPO/GRPO training

RL with RoboCasa Benchmark
Support RoboCasa+π₀+GRPO training

Real-World RL with Franka
RLinf worker seamlessly integrates with the Franka robotic arm

RL with Franka-Sim Benchmark
Supports Franka-Sim + MLP/CNN + PPO/SAC training

RL with RoboTwin Benchmark
Supports RoboTwin + OpenVLA-OFT / π₀ / π₀.₅ + PPO / GRPO training

SAC-Flow Policy Training
Train a Flow Matching policy with SAC (Sim & Real)

MLP Policy Training
Train an MLP Policy with PPO/SAC/GRPO
RL with OpenSora World Model
Support OpenSora World Model + OpenVLA-OFT + GRPO training

RL with GSEnv for Real2Sim2Real
Support GSEnv + π₀.₅ + PPO training
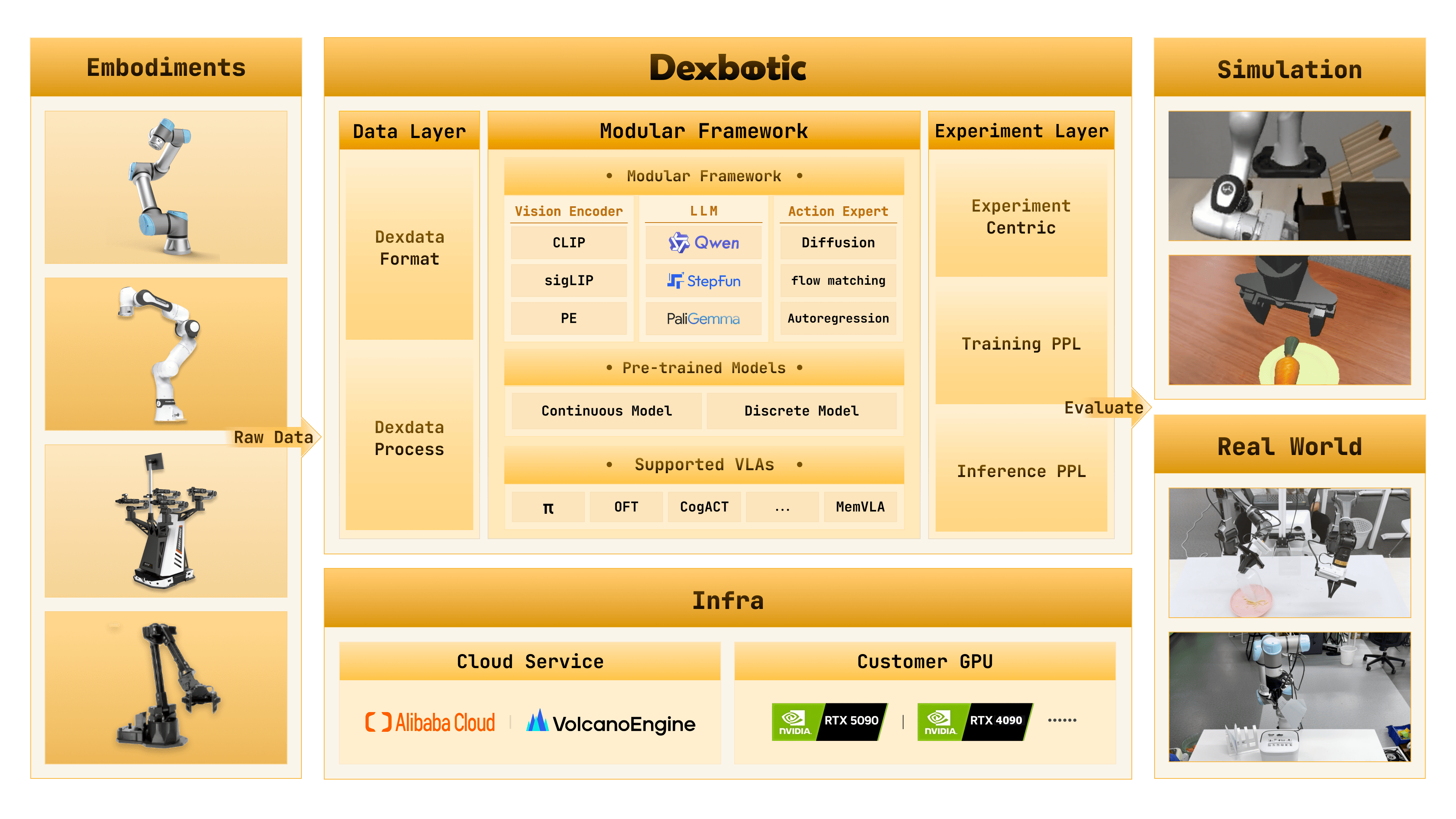
RL on Dexbotic Model
Dexbotic (π₀.₅-based) + LIBERO + PPO training

RL with Wan World Model
Support Wan World Model + OpenVLA-OFT + GRPO training
Sim-Real Co-Training
PPO in sim + SFT on real data for better sim-to-real transfer

DSRL for Pi0
Steer a frozen Pi0 diffusion policy with lightweight SAC in noise space

Real-World RL with XSquare Turtle2
SAC + CNN policy on the XSquare Turtle2 dual-arm robot