具身智能场景#
具身智能场景包含SOTA模型(如pi0、pi0.5、OpenVLA-OFT)和不同模拟器(如LIBERO、ManiSkill、RoboTwin、MetaWorld)的训练示例,以及真机强化学习训练示例等。
基于ManiSkill的强化学习
ManiSkill+OpenVLA+PPO/GRPO达到SOTA训练效果

基于LIBERO的强化学习
LIBERO+OpenVLA-OFT+GRPO成功率达99%
π₀和π₀.₅模型强化学习训练
在π₀和π₀.₅上实现强化学习的效果跃升

基于Behavior的强化学习
支持Behavior+OpenVLA-OFT+PPO/GRPO训练

基于MetaWorld的强化学习
支持MetaWorld+π₀/π₀.₅+PPO/GRPO训练

基于IsaacLab的强化学习
支持IsaacLab+gr00t+PPO训练

GR00T-N1.5模型强化学习训练
支持GR00T-N1.5强化学习微调

基于CALVIN的强化学习
支持CALVIN+π₀/π₀.₅+PPO/GRPO训练

基于RoboCasa的强化学习
支持RoboCasa+π₀+GRPO训练

Franka真机强化学习
RLinf worker无缝对接Franka机械臂

基于Franka-Sim的强化学习
支持Franka-Sim+MLP/CNN+PPO/SAC训练

基于RoboTwin的强化学习
支持RoboTwin + OpenVLA-OFT/π₀/π₀.₅ + PPO/GRPO训练

SAC-Flow 策略训练
使用 SAC 训练 Flow Matching 策略 (Sim & Real)

基于MLP的强化学习
使用 PPO/SAC/GRPO 训练 PPO 策略
基于 OpenSora 世界模型的强化学习
支持 OpenSora 世界模型 + OpenVLA-OFT + GRPO 训练

基于 GSEnv 的 Real2Sim2Real 强化学习
支持 GSEnv + π₀.₅ + PPO 训练
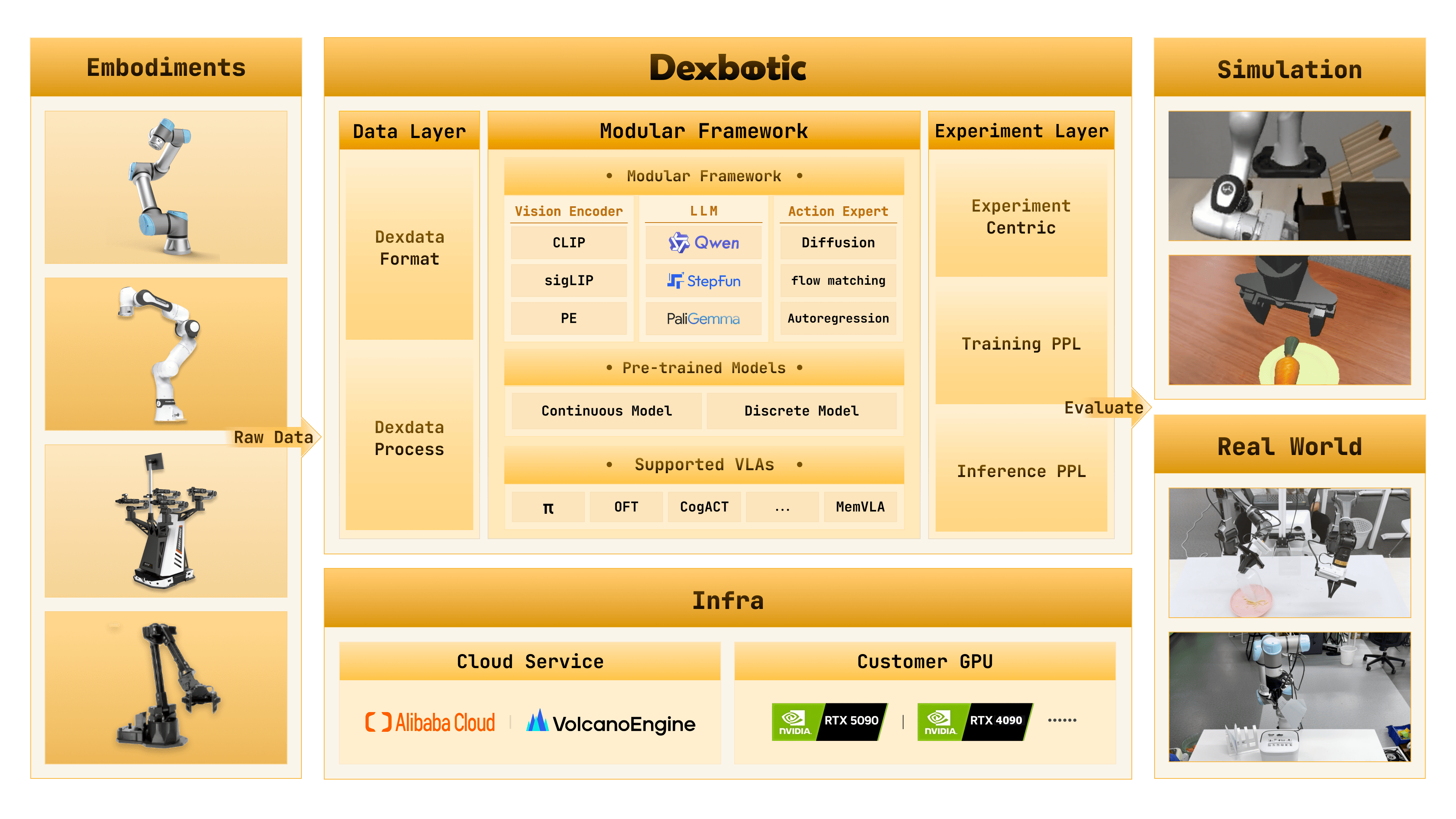
基于 Dexbotic 模型的强化学习训练
Dexbotic(基于 π₀.₅)+ LIBERO + PPO 训练

基于 Wan 世界模型的强化学习
支持 Wan 世界模型 + OpenVLA-OFT + GRPO 训练
仿真-真机协同训练
仿真 PPO + 真机 SFT,提升 Sim-to-Real 迁移

DSRL:Pi0 噪声空间强化学习
用轻量级 SAC 智能体在噪声空间引导冻结的 Pi0 扩散策略

XSquare Turtle2 真机强化学习
SAC + CNN 策略在 XSquare Turtle2 双臂机器人上的真机训练