VLA / WAM 模型的强化学习#
本类示例以 视觉-语言-动作(VLA)模型 或 世界-动作模型(WAM) 为主线,展示如何在 RLinf 中接入特定模型家族 —— 包括 checkpoint 加载、processor / config 接线、动作头实现,以及一份不依赖具体基准的强化学习微调参考配方。
如果你的出发点是 "我想对模型 X 做 RL 微调",这里是合适的入口。若以基准为主线请参考 基于模拟器的具身强化学习。
π₀和π₀.₅模型强化学习训练
在π₀和π₀.₅上实现强化学习的效果跃升

GR00T模型强化学习训练
支持GR00T-N1.5,N1.6与N1.7强化学习微调

基于 Lingbot-VLA 模型的强化学习
支持 Lingbot-VLA + RoboTwin + GRPO 训练
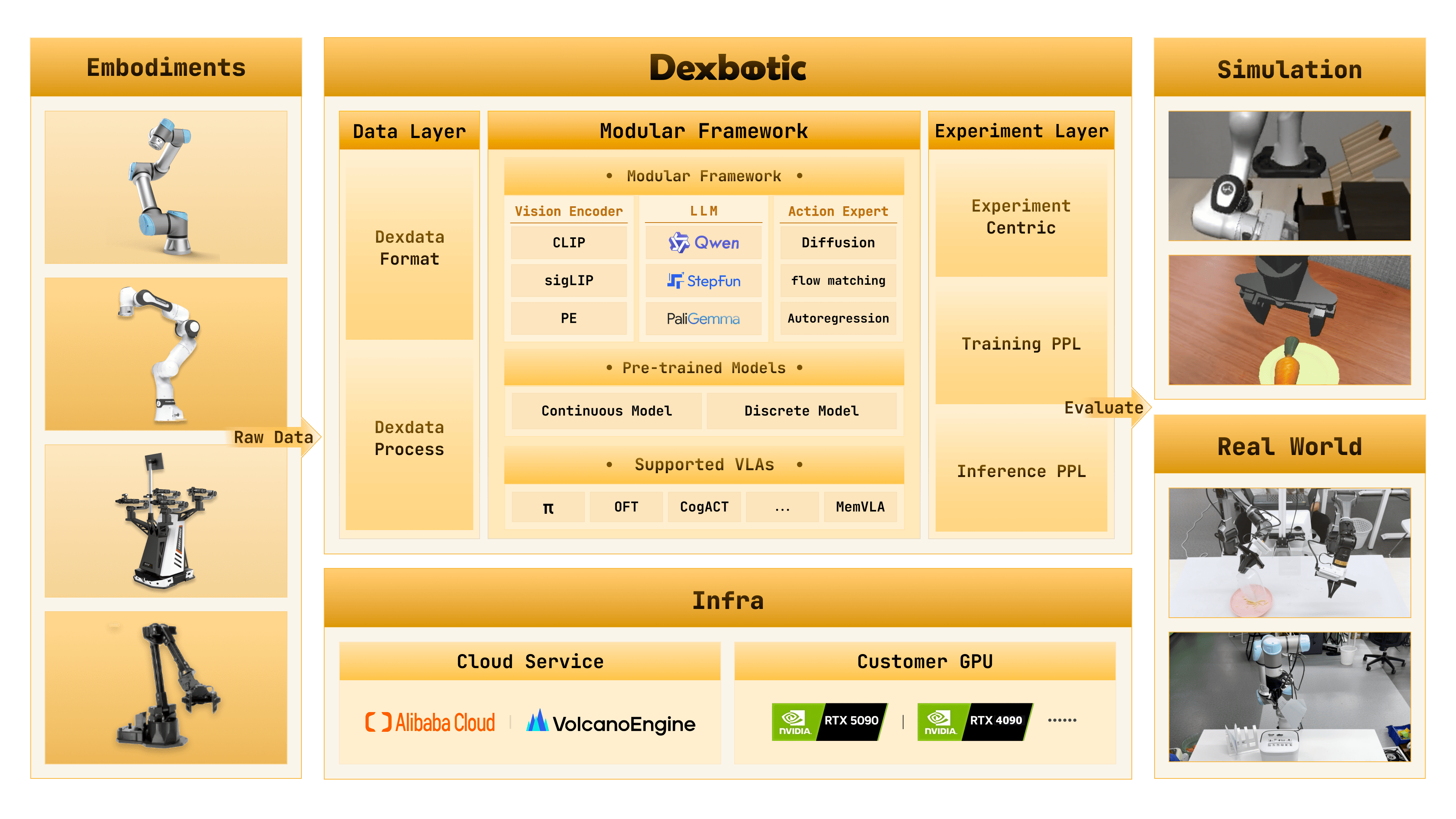
基于 Dexbotic 模型的强化学习训练
Dexbotic(基于 π₀.₅)+ LIBERO + PPO 训练

StarVLA 模型强化学习训练
StarVLA + LIBERO + GRPO 具身强化学习训练
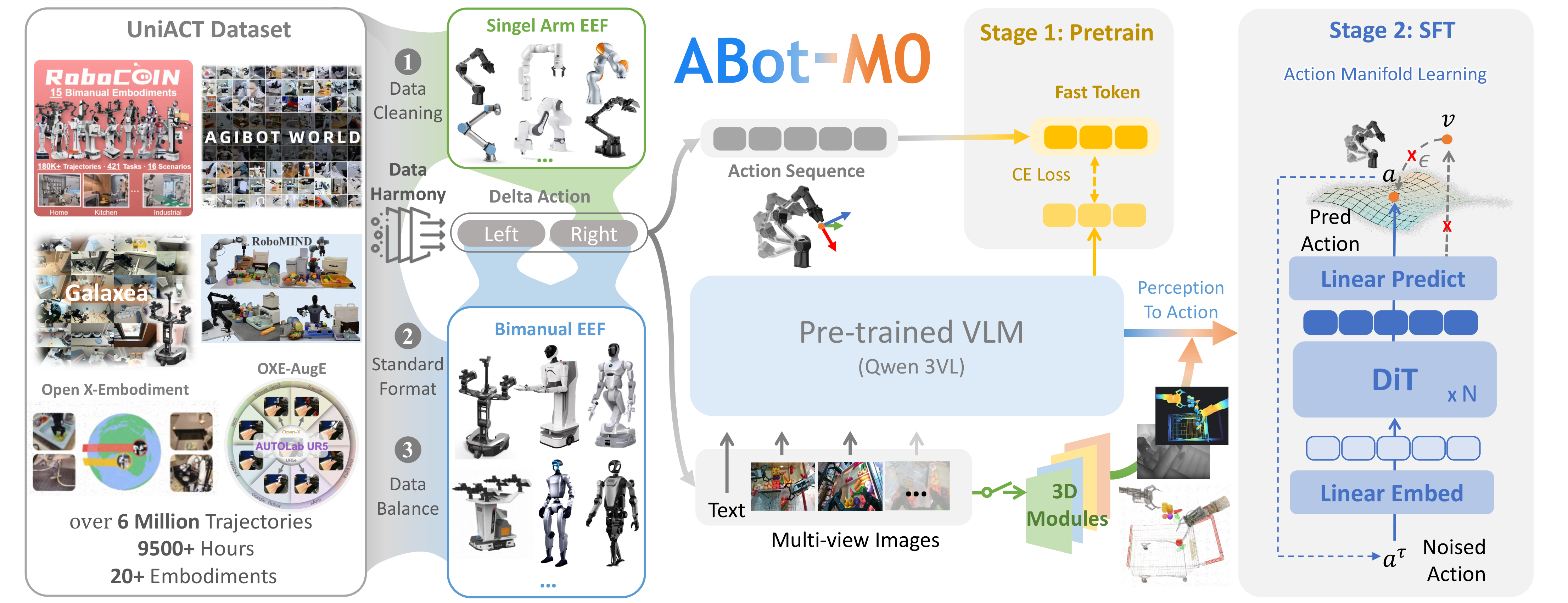
ABot-M0 模型强化学习训练
ABot-M0 原生集成与 LIBERO-plus PPO 训练
基于 OpenSora 世界模型的强化学习
支持 OpenSora 世界模型 + OpenVLA-OFT + GRPO 训练

基于 Wan 世界模型的强化学习
支持 Wan 世界模型 + OpenVLA-OFT + GRPO 训练