GR00T模型强化学习训练#
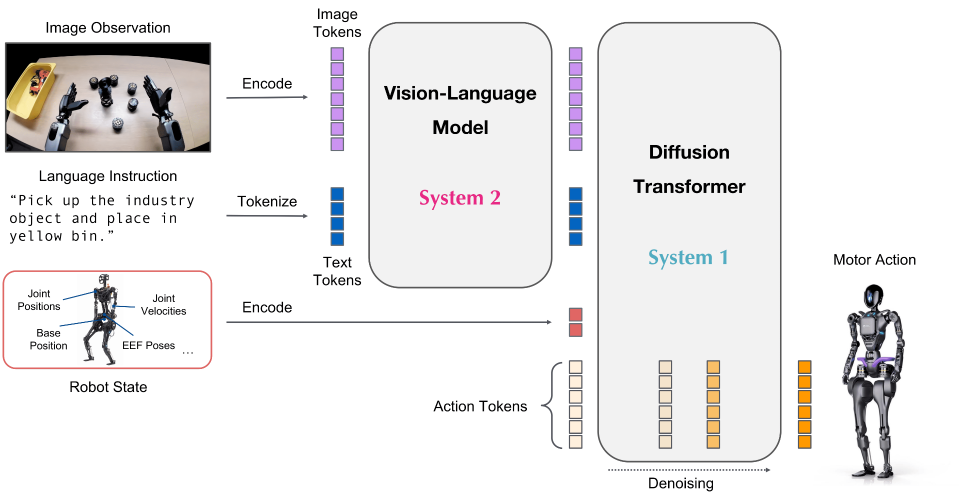
NVIDIA GR00T:跨具身的 VLA 基础模型。#
使用 RLinf 在 LIBERO 上对 GR00T 模型进行强化学习微调——SFT 冷启动、PPO 训练、评估与可视化。
备注
RLinf 同时支持 GR00T-N1.5、GR00T-N1.6 和 GR00T-N1.7。N1.6 引入了流匹配动作头、FSDP 训练和更强的跨具身支持;N1.7 则进一步将官方 backbone 升级到 Cosmos-Reason2-2B / Qwen3-VL,并显著扩展了官方通用 state/action 空间。版本差异以 N1.5 / N1.6 / N1.7 标注区分。
概览#
在 LIBERO 上用 PPO(actor-critic)微调 GR00T(N1.5 / N1.6 / N1.7)。
LIBERO · IsaacLab
PPO
LIBERO Spatial · Object · Goal · Long
1 节点 · GPU
run_embodiment.sh → 观察 env/success_once。任务#
根据环境、任务族以及配置或权重工件选择对应的模型页面。
环境 |
任务 / 套件 |
配置 / 权重 |
重点 |
|---|---|---|---|
LIBERO |
LIBERO-Spatial |
|
在 spatial 操作任务上使用 GR00T-N1.x 与 Flow-SDE PPO。 |
LIBERO |
LIBERO-Object |
|
使用 GR00T 进行物体操作微调。 |
LIBERO |
LIBERO-Goal |
|
进行目标条件操作微调。 |
LIBERO |
LIBERO-10 |
|
使用 GR00T 进行长程 LIBERO 训练。 |
观测与动作#
字段 |
说明 |
|---|---|
Observation |
GR00T dataconfig 所需的多视角 RGB 图像与机器人本体状态。 |
Action |
GR00T 策略生成的连续动作块。 |
Reward |
PPO 使用的 LIBERO 任务成功信号或仿真器奖励。 |
Prompt |
每个 LIBERO episode 提供的自然语言任务 prompt。 |
安装#
首先,克隆 RLinf 仓库:
# 为提高国内下载速度,可以使用镜像:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
然后,使用下列两种方式之一准备依赖:预构建的 Docker 镜像(推荐)或自定义环境。
通用的安装流程(前置依赖、GPU 驱动、镜像内置的 switch_env 工具、镜像加速、常见问题排查)
在 安装说明 中统一说明;本方案中的命令仅在 Docker
镜像标签和 --env 取值上有所不同。
选项 1:Docker 镜像 —— 镜像标签 agentic-rlinf0.3-maniskill_libero:
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 如果需要国内加速下载镜像,可以使用:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
请通过镜像内置的 switch_env 工具切换到对应的虚拟环境:
N1.5:
source switch_env gr00t
N1.6:
source switch_env gr00t_n1d6
N1.7:
source switch_env gr00t_n1d7
选项 2:自定义环境
N1.5:
# 为提高国内依赖安装速度,可以添加``--use-mirror``到下面的install.sh命令
bash requirements/install.sh embodied --model gr00t --env maniskill_libero
source .venv/bin/activate
N1.6:
# 为提高国内依赖安装速度,可以添加``--use-mirror``到下面的install.sh命令
bash requirements/install.sh embodied --model gr00t_n1d6 --env maniskill_libero
source .venv/bin/activate
N1.7:
# 为提高国内依赖安装速度,可以添加``--use-mirror``到下面的install.sh命令
bash requirements/install.sh embodied --model gr00t_n1d7 --env maniskill_libero
source .venv/bin/activate
下载模型#
开始训练前,您需要下载相应的预训练模型。
N1.5: GR00T-N1.5 少样本SFT模型下载
目前我们支持四种libero任务:Spatial, Object, Goal, and Long。
# 方法1:使用git clone
git lfs install
git clone https://huggingface.co/RLinf/RLinf-Gr00t-SFT-Spatial
# 方法2:使用huggingface-hub
# 为提升国内下载速度,可以设置:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-Gr00t-SFT-Spatial --local-dir RLinf-Gr00t-SFT-Spatial
其他任务的SFT模型下载: - Libero-Object - Libero-Goal - Libero-Long
N1.6: GR00T-N1.6 SFT模型
目前提供libero Spatial 任务,并作为GR00T N1.6的示例:
# 方法1:使用git clone
git lfs install
git clone https://huggingface.co/RLinf/RLinf-Gr00t-N1.6-SFT-Spatial
# 方法2:使用huggingface-hub
# 为提升国内下载速度,可以设置:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-Gr00t-N1.6-SFT-Spatial --local-dir RLinf/RLinf-Gr00t-N1.6-SFT-Spatial
N1.7:当前临时使用官方 release checkpoint
RLinf 目前还没有提供一个由本仓库产出的、专门用于这个 RL 示例的 GR00T-N1.7 SFT checkpoint。因此,在当前仓库状态下,维护中的 N1.7 RL 示例暂时直接使用官方发布的 LIBERO checkpoint 作为任务 checkpoint 起点。
换句话说:
model_path当前指向的是本地官方nvidia/GR00T-N1.7-LIBEROcheckpoint,而不是本仓库导出的 N1.7 SFT checkpoint。backbone_model_path指向本地Cosmos-Reason2-2Bcheckpoint,以便 actor、rollout 和 processor 全部离线运行。
对应官方 N1.7 文档里的核心升级方向:
Relative EEF Action Space:N1.7 使用机器人与人类具身共享的 relative EEF 动作空间,以当前位姿增量而不是绝对目标来表达动作,这是其跨具身泛化能力的重要原因之一。
Human Video Pretraining:N1.7 在多样机器人示范之外,还联合使用了 20K 小时 EgoScale 人类视频进行预训练,因此可以将从人类视频中学到的操作先验迁移到机器人控制。
Key Changes from N1.6:N1.7 将 VLM backbone 升级为
Cosmos-Reason2-2B/ Qwen3-VL,简化了数据处理流水线,并增强了 ONNX / TensorRT 导出支持。
在 RLinf 自己的 N1.7 SFT checkpoint 发布之前,可以先按下面的方式离线下载官方模型:
# 为提升国内下载速度,可以设置:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
# 下载 Cosmos-Reason2-2B backbone
uv run hf download nvidia/Cosmos-Reason2-2B \
--local-dir checkpoints/Cosmos-Reason2-2B
# 下载 GR00T-N1.7-LIBERO 任务 checkpoint(仅 libero_spatial 所需文件)
uv run hf download nvidia/GR00T-N1.7-LIBERO \
--include "libero_spatial/config.json" \
"libero_spatial/embodiment_id.json" \
"libero_spatial/model-*.safetensors" \
"libero_spatial/model.safetensors.index.json" \
"libero_spatial/processor_config.json" \
"libero_spatial/statistics.json" \
--local-dir checkpoints/GR00T-N1.7-LIBERO
当前示例使用这组最小文件即可运行。如果你的本地 checkpoint 目录里还能保留 experiment_cfg/metadata.json,建议一并保留;RLinf 在存在该文件时会优先使用它,但即使缺失也可以回退到 modality/config 推断。
当前维护中的 RLinf N1.7 RL 示例仅为 LIBERO Spatial。
GR00T 核心设计理念#
N1.5:
1. 模态配置(Modality Config)
模态配置是GR00T-N1.5中一项关键且突出的设计特性。 通过定义统一的数据集接口,它使不同的机器人配置能够利用相同的数据集。例如,双臂数据集可通过这一创新设计用于训练单臂模型。为实现此功能,GR00T-N1.5采取了以下关键措施。
1.1 增强的LeRobot数据集
LeRobot数据集包含一个meta文件夹,其中详细记录了数据集的所有元数据。 GR00T-N1.5进一步定义了一个modality.json文件,用于确定数据集的数据接口。
1.2 DataConfig类
GR00T-N1.5引入了DataConfig类,用于描述模型训练所需的所有信息。 它将数据集和机器人配置解耦,使模型能够在不同机器人之间进行训练,而无需修改数据处理代码。该类还定义了所有数据模态的转换方式。
1.3 具身标签(Embodiment Tag)
具身标签是一个枚举值,用于确定训练过程中使用哪个DataConfig。模型还会根据此标签采用不同的状态和动作编码器/解码器。
2. 微调指南
基于上述设计,除LIBERO外,在新环境中部署GR00T-N1.5之前,用户需要对其进行微调。 微调指南可在 GR00T-N1.5官方仓库的getting_started/finetune_new_embodiment.md 中找到。
微调后,GR00T-N1.5会生成一个``experiment_cfg/metadata.json``文件,其中包含所有模态配置和微调数据集的统计信息。 该文件对于GR00T-N1.5的推理和强化学习后训练至关重要。 更多细节请参考 GR00T-N1.5官方仓库的getting_started/GR00T_inference.ipynb。
N1.6:
1. 两阶段解耦训练范式
RLinf 框架针对GR00T-N1.6采用了高度解耦的两阶段训练架构:
第一阶段(纯 SFT 预热):采用``Pure SFT Model``模式。模型完全脱离物理仿真环境,仅依赖离线专家数据集进行监督微调,专注拟合目标动作轨迹。
第二阶段(PPO 强化对齐):在SFT收敛的基础上,将模型载入基于FSDP的分布式Actor中,与仿真环境进行实时交互。
2. 极简的局部微调策略
为了在大幅节省显存的同时防止"灾难性遗忘",框架默认采用"冻结主干"策略:
主干冻结:在SFT和后续RL阶段中,视觉-语言主干网络将被严格锁定(
requires_grad=False)。专注动作头:仅解冻动作输出头参与梯度更新。
3. 流匹配动作生成(Flow-Matching Action Head)
模型通过加噪与去噪的流匹配机制(Flow-SDE / Diffusion),直接在连续空间中生成高频动作块。
关键配置:通过
num_action_chunks控制预测步长,denoising_steps控制去噪深度。
4. 跨具身泛化(Cross-Embodiment)
具身标签(Embodiment Tag):依靠传入的配置标签(如``ROBOCASA_PANDA_OMRON``),系统能动态适配对应的状态编码器与动作空间。无论是单臂机械臂,还是四足机器人形态均可复用。
5. FSDP 分布式并行架构
底层系统针对Actor节点进行了重构(
EmbodiedFSDPActor),能够跨GPU节点对模型权重、梯度与优化器状态进行分片切分(Sharding)。鉴于GR00T-N1.6参数规模的显著增长,RLinf的Actor节点已全面重构,打破了传统DDP的单卡显存瓶颈,极大提升了吞吐量。
微调完成后,系统将在输出目录生成``metadata.json``等统计文件,保留推理和后续部署所需的关键模态信息。
N1.7:
1. 官方 N1.7 的核心新变化
GR00T N1.7 建立在 N1.6 之上,引入了新的 VLM backbone 以及一系列代码层面的改进。
Relative EEF Action Space:N1.7 采用机器人与人类具身共享的 relative end-effector 动作空间。相较于用绝对目标表达动作,使用相对当前位姿的增量表达能显著提升泛化能力,这也是其跨具身表现的重要原因之一。
Human Video Pretraining:N1.7 联合使用了 20K 小时 EgoScale 人类视频和多样化机器人示范进行预训练。由于 relative EEF 动作表示在机器人和人类数据之间是一致的,模型能将从人类视频中学到的操作先验更直接地迁移到机器人控制。
2. 相对 N1.6 的关键变化
官方 backbone 升级为
nvidia/Cosmos-Reason2-2B,采用 Qwen3-VL 风格架构,替代了 N1.6 所使用的 Eagle backbone。官方
processing_gr00t_n1d7.py路径相较 N1.6 简化了数据处理流水线。官方 N1.7 还增强了完整的 ONNX / TensorRT 导出支持。
官方 N1.7 模型配置将默认通用上限提升为
max_state_dim=132、max_action_dim=132和action_horizon=40。
3. RLinf 当前的 checkpoint 策略
RLinf 目前还没有为这个 RL 示例提供一个由仓库自产出的 N1.7 SFT checkpoint。
因此,当前维护中的示例暂时使用官方发布的
GR00T-N1.7-LIBERO/libero_spatialcheckpoint 作为model_path。
4. RLinf 的 N1.7 接口适配
在当前 RLinf 实现中,LIBERO 的原始 state 在转换前是 8 维,而官方 N1.7 模型内部使用的是更大的通用 state/action 表示。
当前 LIBERO 示例使用
embodiment_tag: libero_sim,并在共享的环境动作工具中应用 LIBERO 的 gripper 约定。
5. Checkpoint 与 processor 契约
RLinf 直接从 checkpoint 目录加载官方 processor。
在离线或镜像环境中,
backbone_model_path可将官方 backbone id 重定向到本地Cosmos-Reason2-2Bsnapshot。
6. 本仓库中的 RL 训练契约
当前维护中的 RLinf N1.7 RL 示例为
examples/embodiment/config/libero_spatial_ppo_gr00t_n1d7.yaml。当前 RL 设置使用 PPO 且
algorithm.loss_type: actor_critic,因此训练时必须保证actor.model.add_value_head为True。当前仓库中经过验证的 LIBERO 示例使用
num_action_chunks: 16和denoising_steps: 4。
运行#
1. 关键集群配置
cluster:
num_nodes: 1
component_placement:
env,rollout,actor: all
您可以将env、rollout和actor组件的放置配置为共享所有GPU。
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
rollout:
pipeline_stage_num: 2
您也可以灵活配置env、rollout和actor组件的GPU数量,并通过``pipeline_stage_num``实现rollout与env之间的流水线重叠。
cluster:
num_nodes: 1
component_placement:
env: 0-1
rollout: 2-5
actor: 6-7
您还可以将组件完全分离,各自使用独立GPU,无需卸载功能。
2. 模型关键参数配置
N1.5:
model:
num_action_chunks: 5
denoising_steps: 4
rl_head_config:
noise_method: "flow_sde"
noise_level: 0.5
disable_dropout: True
您可以调整noise_level和denoising_steps来控制噪声强度和流匹配步骤。 num_action_chunks决定了将用于前向仿真环境的未来步骤数量。 GR00T-N1.5的动作头包含dropout层,这会干扰对数概率的计算,因此需将disable_dropout设置为True,以将其替换为恒等层。 可通过noise_method选择不同的噪声注入方法。我们提供两种选项: flow-sde 和 flow-noise。
N1.6:
Actor 模型与动作头配置
model:
model_type: "gr00t_n1d6"
add_value_head: True # 强化学习关键:动态注入价值网络预测优势
num_action_chunks: 16 # 每次推理预测的未来动作步数
denoising_steps: 4 # 控制流匹配(Flow-Matching)去噪步数
FSDP 分布式切片策略
fsdp_config:
wrap_policy:
transformer_layer_cls_to_wrap:
- "Qwen3DecoderLayer"
- "Siglip2EncoderLayer"
N1.7:
Actor 模型与动作头配置
model:
model_type: "gr00t_n1d7"
add_value_head: True
num_action_chunks: 16
denoising_steps: 4
运行时路径配置
model:
model_path: "/path/to/GR00T-N1.7-LIBERO/libero_spatial"
backbone_model_path: "/path/to/Cosmos-Reason2-2B"
PPO 与优化器超参数
algorithm:
adv_type: gae
clip_ratio_high: 0.2
gamma: 0.99
gae_lambda: 0.95
optim:
lr: 5.0e-6
value_lr: 1.0e-4
clip_grad: 1.0
3. 配置文件
N1.5:
GR00T-N1.5 + PPO + Libero-Spatial:
examples/embodiment/config/libero_spatial_ppo_gr00t.yamlGR00T-N1.5 + PPO + Libero-Object:
examples/embodiment/config/libero_object_ppo_gr00t.yamlGR00T-N1.5 + PPO + Libero-Goal:
examples/embodiment/config/libero_goal_ppo_gr00t.yamlGR00T-N1.5 + PPO + Libero-Long:
examples/embodiment/config/libero_10_ppo_gr00t.yaml
N1.6:
GR00T-N1.6 + PPO + Libero-Spatial:
examples/embodiment/config/libero_spatial_ppo_gr00t_n1d6.yaml
需要修改SFT后模型的路径:
model:
model_path: "/path/to/RLinf-Gr00t-N1.6-RL-Spatial"
N1.7:
GR00T-N1.7 + PPO + Libero-Spatial:
examples/embodiment/config/libero_spatial_ppo_gr00t_n1d7.yaml
需要修改模型路径和 backbone 路径:
model:
model_path: "/path/to/GR00T-N1.7-LIBERO/libero_spatial"
backbone_model_path: "/path/to/Cosmos-Reason2-2B"
4. 启动命令
N1.5:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_gr00t
bash examples/embodiment/run_embodiment.sh libero_object_ppo_gr00t
bash examples/embodiment/run_embodiment.sh libero_goal_ppo_gr00t
bash examples/embodiment/run_embodiment.sh libero_10_ppo_gr00t
N1.6:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_gr00t_n1d6
N1.7:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_gr00t_n1d7
可视化与结果#
1. TensorBoard日志
# 启动TensorBoard
tensorboard --logdir ./logs --port 6006
2. 关键指标
关注任务成功率指标 env/success_once。各项指标的含义见
训练指标。
3. 视频生成
video_cfg:
save_video: True
info_on_video: True
video_base_dir: ${runner.logger.log_path}/video/train
4. WandB集成
runner:
task_type: embodied
logger:
log_path: "../results"
project_name: rlinf
experiment_name: "libero_spatial_ppo_gr00t"
logger_backends: ["tensorboard", "wandb"] # tensorboard, wandb, swanlab
LIBERO结果
N1.5:
模型 |
Spatial |
Object |
Goal |
Long |
Average |
Δ Avg. |
|---|---|---|---|---|---|---|
GR00T(少样本) |
52.5% |
--- |
||||
+PPO |
89.5% |
+37.0% |
我们想指出上述结果使用了与 \(\pi_0\) 相同的超参数设置。这些发现主要展示了所提出RL训练框架的广泛适用性和鲁棒性。通过参数调优可以更进一步提升模型性能。
N1.6:

GR00T-N1.6 SFT + PPO在 LIBERO_Spatial 的成功率曲线
N1.7:
模型 |
Spatial |
|---|---|
GR00T-N1.7 PPO |
|