智能体场景#
RLinf的worker抽象、灵活的通信组件、以及对不同类型加速器的支持使RLinf天然支持智能体工作流的构建,以及智能体的训练。以下示例包含数学推理强化学习与智能体 AI 工作流,例如智能体工作流构建、在线强化学习训练、环境接入,以及 以推理为中心的智能体强化学习 等场景。
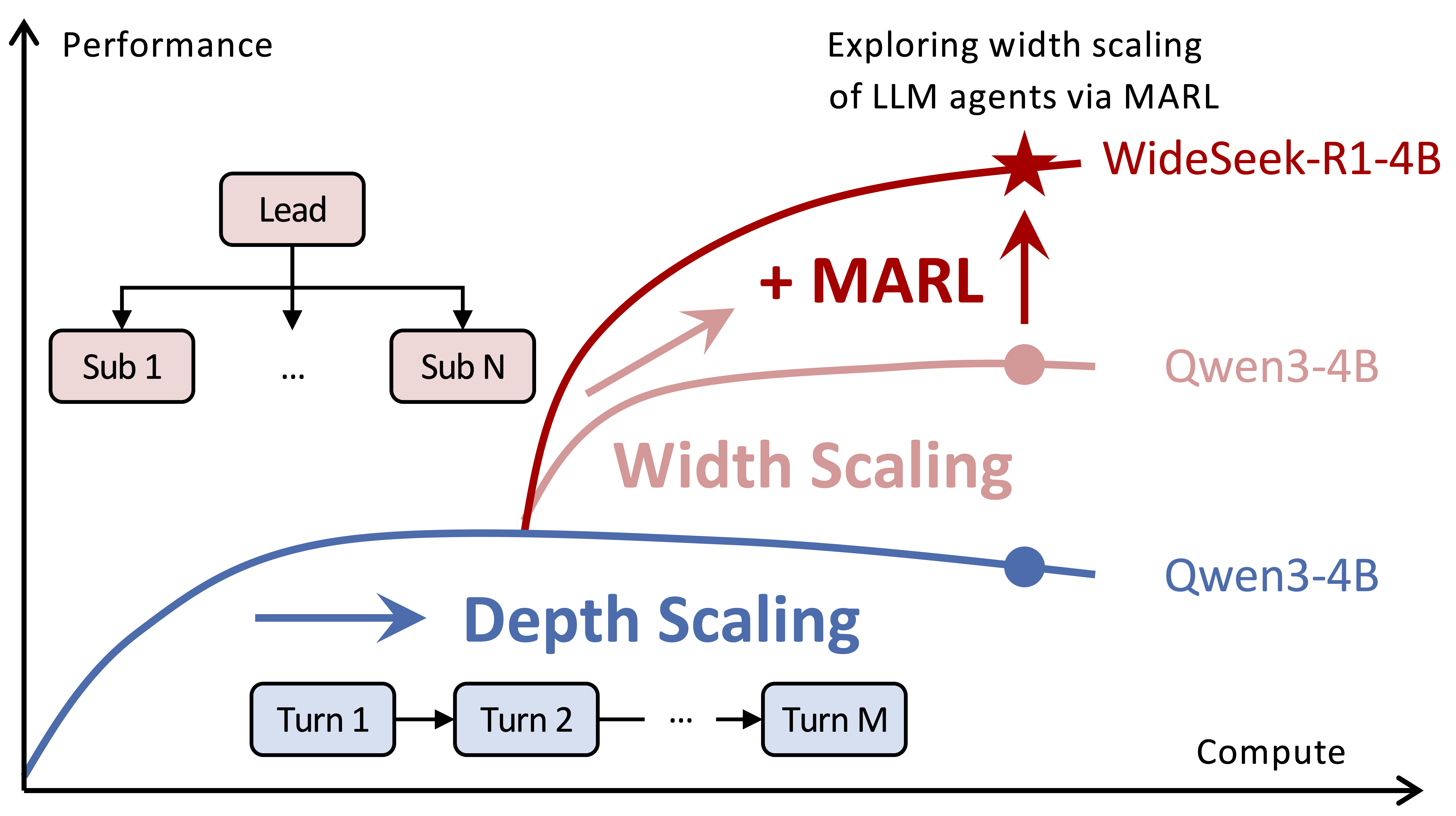
WideSeek-R1
通过多智能体强化学习探索用于广泛信息检索的宽度扩展方法
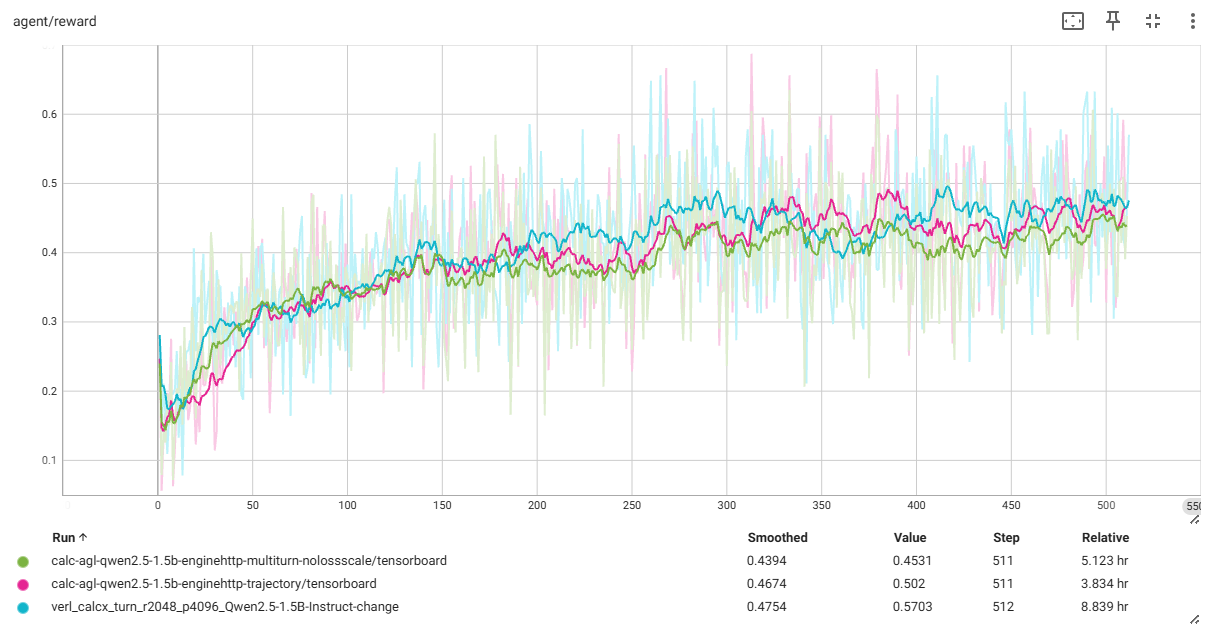
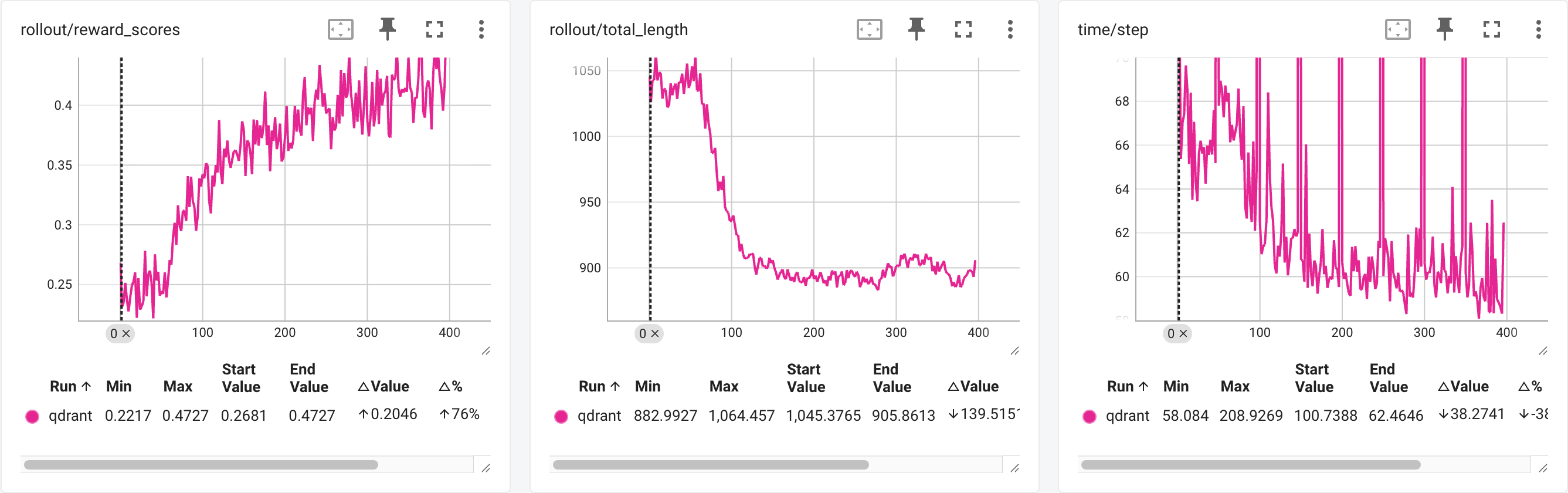
AgentLightning Calc-X
基于 Agent Lightning 编排智能体强化学习,RLinf 作为分布式训练后端
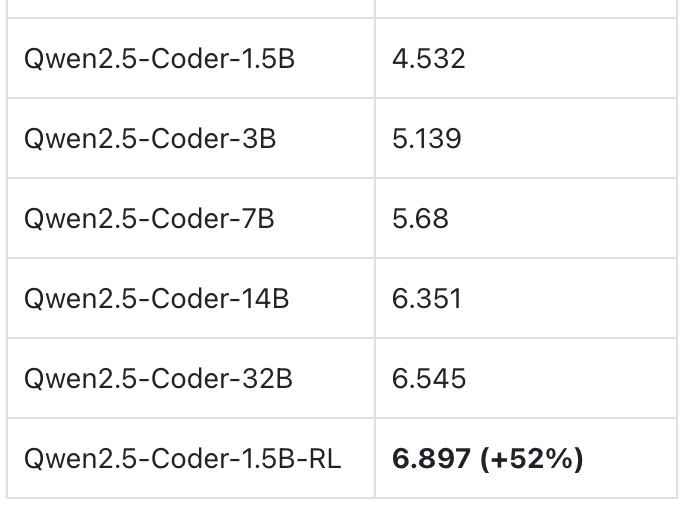
代码补全在线强化学习开源版
基于RLinf+continue实现端到端在线强化学习,模型效果提升52%
Search-R1强化学习
训练LLM调用搜索工具回答问题,RLinf加速训练过程55%
rStar2-agent强化学习
通过强化学习让模型学会使用Python工具进行自主推理和反思,以极低计算成本达到数学推理领域的顶尖水平
[适配中]SWE-agent
部署、推理、训练一体,高灵活性、高性能
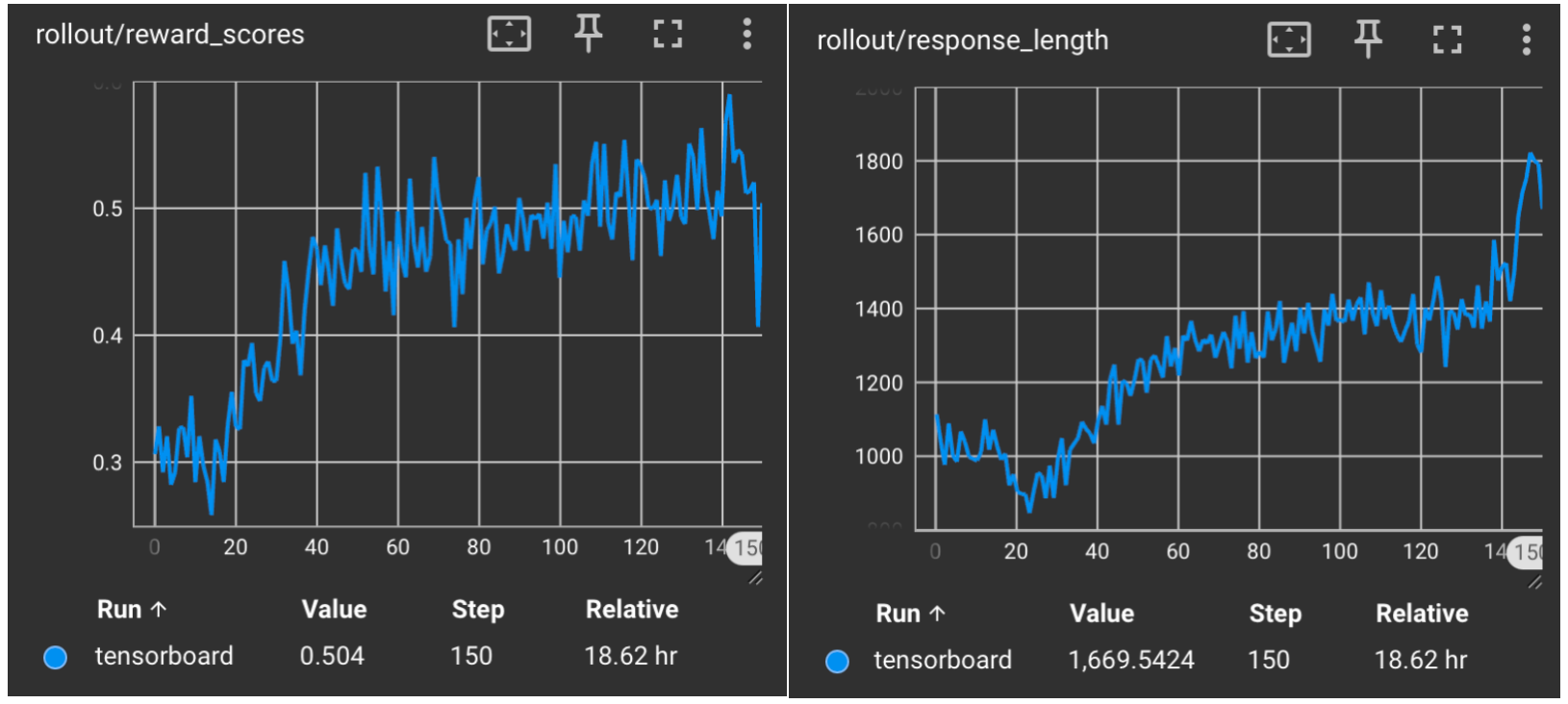
使用 GRPO 训练 Math 推理任务
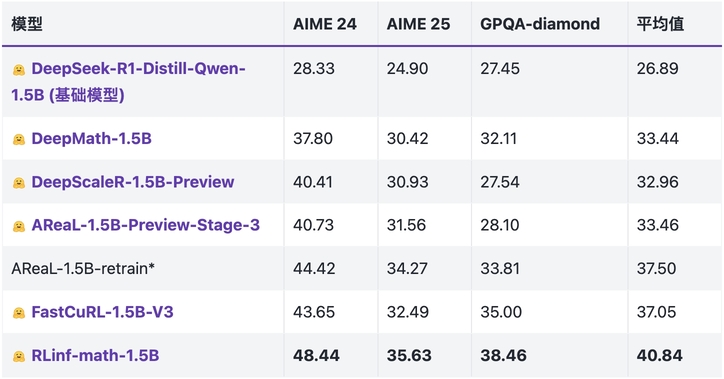
使用强化学习提升数学推理能力,在 AIME24/AIME25/GPQA-diamond 上达到 SOTA
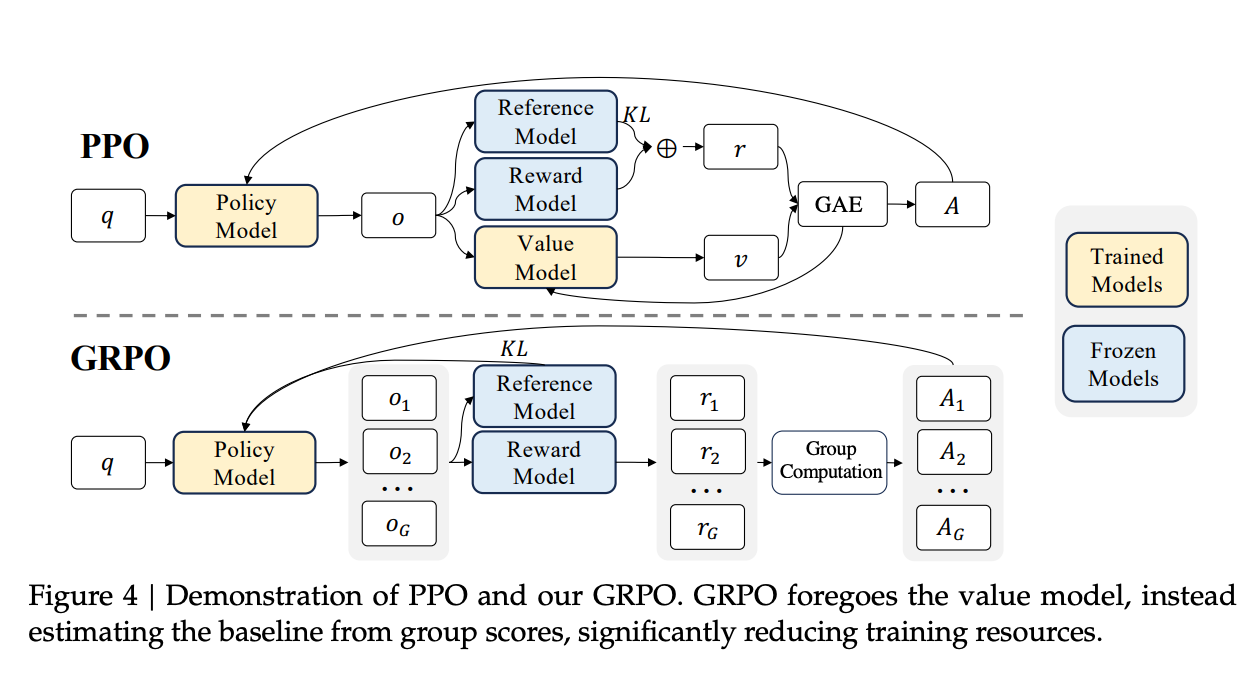
使用 PPO 训练 Math 推理任务
使用 PPO 算法进行数学推理强化学习训练,示例配置基于 Qwen2.5-1.5B

使用 GRPO 训练 Qwen3-VL 视觉语言推理
基于 GRPO 的视觉语言模型强化学习训练,用于几何问题求解(Geo3K)