ABot-M0 强化学习训练#
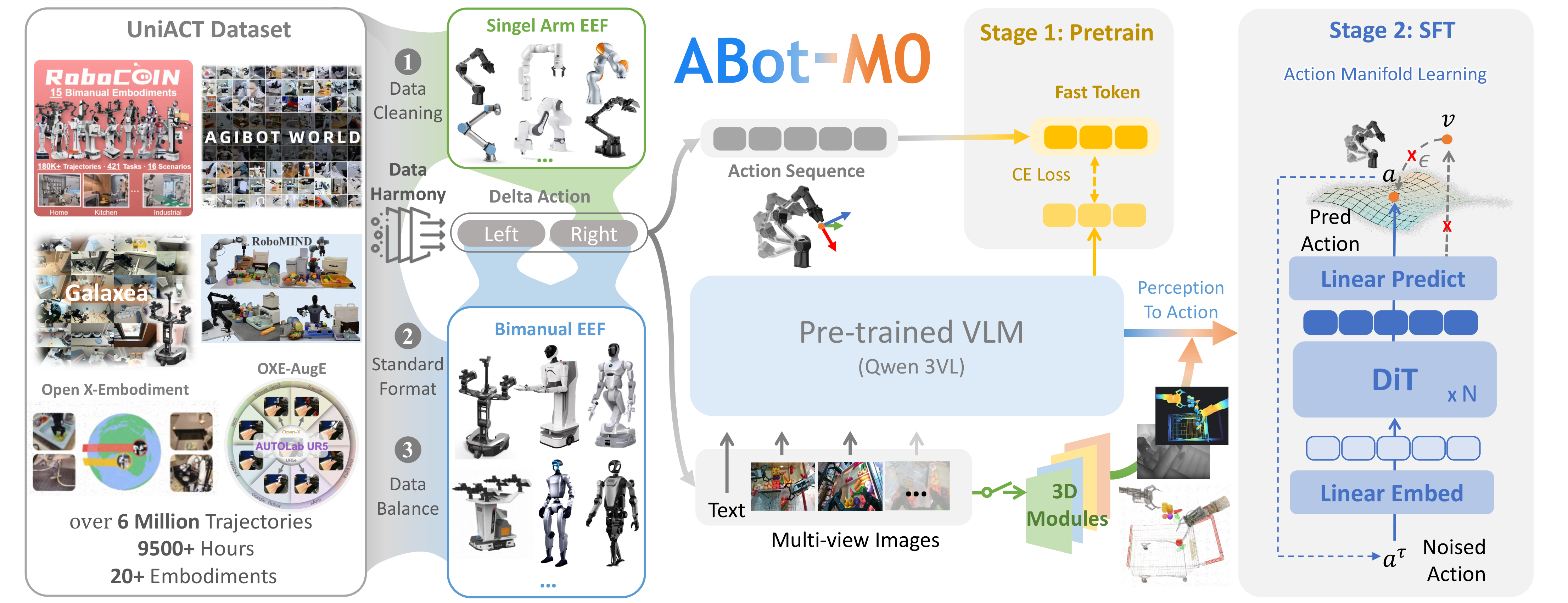
ABot-M0:以 VGGT 为空间基础的 VLA 策略。#
在 RLinf 中对 ABot-M0 进行评测与 PPO 训练,覆盖标准 LIBERO 与 LIBERO-Plus。该适配使用 HuggingFace rollout backend 与 FSDP actor 训练:rollout 阶段 ABot-M0 生成动作块,actor 更新阶段 RLinf 基于 rollout 中保存的输入重新计算 log probability 与 value。
概览#
在 LIBERO-10 / LIBERO-Plus 上用 PPO(actor-critic)微调 ABot-M0。
LIBERO · LIBERO-Plus
PPO
LIBERO-10
1 节点 · GPU
model_path → 评测 → 启动 run_embodiment.sh → 观察 env/success_once。ABot-M0 作为 VLA 策略接入 RLinf:适配层冻结预训练感知模块,通过 RL objective 训练动作模型, 并额外加入 value head 以支持 actor-critic PPO(GAE 估计 advantage/return、ratio clipping、 value clipping、可选 entropy 正则)。
任务#
根据环境、任务族以及配置或权重工件选择对应的模型页面。
环境 |
任务 / 套件 |
配置 / 权重 |
重点 |
|---|---|---|---|
LIBERO |
LIBERO-10 |
|
针对 ABot-M0 release checkpoint 的 PPO 微调。 |
LIBERO |
LIBERO-10+ |
|
使用 ABot-M0 进行长程 LIBERO-10+ 训练。 |
观测与动作#
字段 |
说明 |
|---|---|
Observation |
ABot-M0 所需的 LIBERO RGB 观测与机器人状态。 |
Action |
从 ABot-M0 策略输出解码的连续机器人动作。 |
Reward |
PPO 使用的 LIBERO 成功信号或任务奖励。 |
Prompt |
每个 LIBERO 任务对应的自然语言指令。 |
安装#
请在同一个 Python 环境中安装 ABot-M0、VGGT 和 LIBERO 运行时。
首先,克隆 RLinf 仓库:
# 为提高国内下载速度,可以使用镜像:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
然后,使用下列两种方式之一准备依赖:预构建的 Docker 镜像(推荐)或自定义环境。
通用的安装流程(前置依赖、GPU 驱动、镜像内置的 switch_env 工具、镜像加速、常见问题排查)
在 安装说明 中统一说明;本方案中的命令仅在 Docker
镜像标签和 --env 取值上有所不同。
选项 1:Docker 镜像 —— 镜像标签 agentic-rlinf0.3-maniskill_libero:
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 国内镜像加速:docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 进入容器后,切换到 ABot-M0 虚拟环境:
source switch_env abot_m0
选项 2:自定义环境 —— 安装套件 --env maniskill_libero。安装脚本会自动克隆 ABot-M0
和 VGGT;若要复用本地 checkout,请先设置 ABOT_PATH / VGGT_PATH:
# 可选:使用本地源码 checkout,而不是由安装脚本自动克隆。
# export ABOT_PATH=<path_to_ABot-Manipulation>
# export VGGT_PATH=<path_to_vggt>
# 为提高国内依赖安装速度,可以添加 --use-mirror。
bash requirements/install.sh embodied --model abot_m0 --env maniskill_libero
source .venv/bin/activate
如果需要运行 LIBERO-Plus 实验,请在同一环境中额外安装 LIBERO-plus 运行时:
# 为提高国内依赖安装速度,可以添加 `--use-mirror` 到下面的 install.sh 命令。
bash requirements/install.sh embodied --model abot_m0 --env liberoplus
source .venv/bin/activate
LIBERO-Plus 资产下载#
LIBERO-Plus 需要大量新增对象、纹理和其他资产才能正常运行。请从 Hugging Face dataset
Sylvest/LIBERO-plus 下载 assets.zip,并解压到已安装的
liberoplus.liberoplus package 目录:
# 获取已安装的 liberoplus 包目录。
# 注意:导入 liberoplus 时可能会触发配置初始化日志,因此使用 tail -n 1 只保留最终路径。
export LIBERO_PLUS_PACKAGE_DIR=$(python -c "import pathlib; import liberoplus.liberoplus as l_plus; print(pathlib.Path(l_plus.__file__).resolve().parent)" | tail -n 1)
echo "LIBERO_PLUS_PACKAGE_DIR=${LIBERO_PLUS_PACKAGE_DIR}"
# 如果运行环境无法直接访问 Hugging Face,可启用镜像。
# export HF_ENDPOINT=https://hf-mirror.com
# 从 Hugging Face dataset 仓库下载资产压缩包。
hf download --repo-type dataset Sylvest/LIBERO-plus assets.zip \
--local-dir "${LIBERO_PLUS_PACKAGE_DIR}"
# assets.zip 内部包含较长的原始路径前缀,因此只提取其中 assets/ 下的内容。
python - <<'PY'
import zipfile
from pathlib import Path
pkg = Path(__import__("os").environ["LIBERO_PLUS_PACKAGE_DIR"])
zip_path = pkg / "assets.zip"
out_dir = pkg / "assets"
with zipfile.ZipFile(zip_path) as z:
for info in z.infolist():
name = info.filename
if "/assets/" not in name:
continue
rel = name.split("/assets/", 1)[1]
if not rel:
continue
target = out_dir / rel
if info.is_dir():
target.mkdir(parents=True, exist_ok=True)
else:
target.parent.mkdir(parents=True, exist_ok=True)
with z.open(info) as src, open(target, "wb") as dst:
dst.write(src.read())
print("Extracted LIBERO-Plus assets to:", out_dir)
PY
# 检查资产目录结构。
ls -lh "${LIBERO_PLUS_PACKAGE_DIR}/assets"
解压完成后,目录应类似如下:
<已安装的 liberoplus 包目录>/
└── assets/
├── articulated_objects/
├── new_objects/
├── scenes/
├── stable_hope_objects/
├── stable_scanned_objects/
├── textures/
├── turbosquid_objects/
├── serving_region.xml
├── wall_frames.stl
└── wall.xml
LIBERO-Plus 的完整说明见 LIBERO 基准文档的 LIBERO-Pro 与 LIBERO-Plus 章节。
下载模型#
训练开始前,请下载 ABot-M0 checkpoint 和所需 backbone 权重:
acvlab/ABot-M0-LIBERO:用于独立评测的 SFT 权重。HaoyunOvO/ABot-m0-LIBERO-10k-step:用于 PPO 训练的 RL baseline。StarVLA/Qwen3-VL-4B-Instruct-Action:Qwen3-VL backbone。facebook/VGGT-1B:运行时无法访问 Hugging Face 时用于离线加载 VGGT。
# 方式 1:使用 git clone
git lfs install
git clone https://huggingface.co/acvlab/ABot-M0-LIBERO
git clone https://huggingface.co/HaoyunOvO/ABot-m0-LIBERO-10k-step
git clone https://huggingface.co/StarVLA/Qwen3-VL-4B-Instruct-Action
git clone https://huggingface.co/facebook/VGGT-1B
# 方式 2:使用 huggingface-hub
# 为提升国内下载速度,可以设置:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download acvlab/ABot-M0-LIBERO --local-dir ./ABot-M0-LIBERO
hf download HaoyunOvO/ABot-m0-LIBERO-10k-step --local-dir ./ABot-m0-LIBERO-10k-step
hf download StarVLA/Qwen3-VL-4B-Instruct-Action --local-dir ./Qwen3-VL-4B-Instruct-Action
hf download facebook/VGGT-1B --local-dir ./VGGT-1B
PPO 训练可使用 10k-step ABot-M0 LIBERO checkpoint 作为 RL baseline。该权重在 LIBERO 评测中的初始成功率约为 40%,适合作为后续 RL 训练的起点。
备注
ABot-M0 checkpoint 自带 config.yaml。下载完成后,请修改 qwenvl.base_vlm,
使其指向本机 Qwen3-VL-4B-Instruct-Action 路径。
qwenvl:
base_vlm: /path/to/Qwen3-VL-4B-Instruct-Action
ABot 当前默认使用 VGGT.from_pretrained("facebook/VGGT-1B") 初始化 VGGT。如果运行时无法访问
Hugging Face 或镜像,请将 VGGT-1B 放入本地 Hugging Face cache,或在 ABot 安装代码中将
VGGT 加载路径显式改为本地目录。
本地路径示例:
self.spatial_model = spatial_model = VGGT.from_pretrained('/workspace/models/VGGT-1B')
配置 model_path#
针对两个 benchmark 各提供一份配置:
LIBERO:
examples/embodiment/config/libero_10_ppo_abot_m0.yamlLIBERO-Plus:
examples/embodiment/config/libero_10_plus_ppo_abot_m0.yaml
请将以下两项设置为用于评测或训练的 checkpoint 路径:
rollout.model.model_pathactor.model.model_path
如果使用 10k-step RL baseline,请设置为:
rollout:
model:
model_path: /path/to/ABot-m0-LIBERO-10k-step/checkpoints/steps_10000_pytorch_model.pt
actor:
model:
model_path: /path/to/ABot-m0-LIBERO-10k-step/checkpoints/steps_10000_pytorch_model.pt
导入完整性验证#
python -c "import rlinf; import ABot; import vggt; print('IMPORT_OK')"
若输出 IMPORT_OK,说明包级依赖链路正常。
独立评测#
训练前请使用统一的 Evaluation 章节验证 ABot-M0 checkpoint。先阅读
LIBERO 评测指南,并在评测配置中同时设置
actor.model.model_path 与 rollout.model.model_path 指向 ABot-M0 checkpoint。
套件 |
配置来源 |
需要修改 |
|---|---|---|
LIBERO-10 |
通过 Evaluation 配置回退使用 |
设置 |
LIBERO-10+ |
通过 Evaluation 配置回退使用 |
设置 |
CLI 用法、Hydra 覆盖、日志和视频输出见 Evaluation CLI 参考 与 Evaluation 结果参考。
运行#
PPO 训练与评测共用同一套启动流程。通过 LIBERO_TYPE 选择目标套件,并启动对应配置。
通用环境变量:
source .venv/bin/activate
export REPO_PATH=$(pwd)
export EMBODIED_PATH=$(pwd)/examples/embodiment
export PYTHONPATH=${REPO_PATH}:$PYTHONPATH
export MUJOCO_GL=egl
export PYOPENGL_PLATFORM=egl
export ROBOT_PLATFORM=LIBERO
ray stop || true
ray start --head --port=6379
LIBERO:
export LIBERO_TYPE=standard
bash examples/embodiment/run_embodiment.sh libero_10_ppo_abot_m0
LIBERO-Plus:
export LIBERO_TYPE=plus
bash examples/embodiment/run_embodiment.sh libero_10_plus_ppo_abot_m0
可视化与结果#
关注任务成功率指标 env/success_once。各项指标的含义见
训练指标。
tensorboard --logdir <runner.logger.log_path> --port 6006