Dexbotic模型强化学习训练#
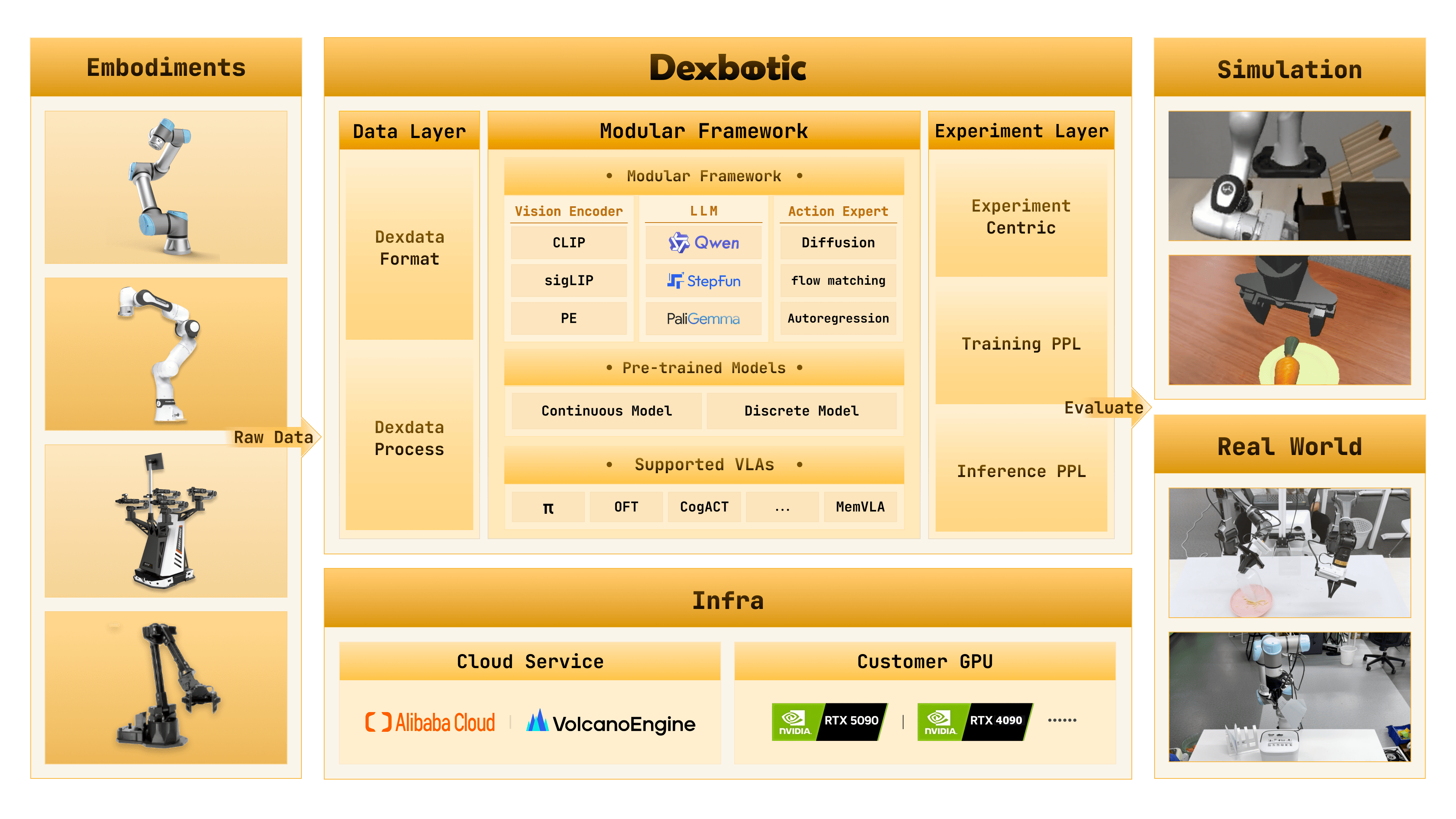
Dexbotic 是 Dexmal 推出的开源 VLA 工具箱。 RLinf 将 Dexbotic π0和 DM0 策略作为 LIBERO 动作生成模型,并使用 PPO 进行在线强化学习微调。
概览#
在 LIBERO 上用 PPO 微调 Dexbotic π0或 DM0。
LIBERO
PPO
LIBERO Spatial · Object · Goal · 10
1 节点 · 8 GPU
run_embodiment.sh → 观察 env/success_once。任务#
根据环境、任务族以及配置或权重工件选择对应的模型页面。
环境 |
任务 / 套件 |
配置 / 权重 |
重点 |
|---|---|---|---|
LIBERO |
LIBERO-Spatial |
|
在 spatial 操作任务上使用 Dexbotic pi0/dm0 策略。 |
LIBERO |
LIBERO-Object |
|
在物体操作任务上使用 Dexbotic pi0。 |
LIBERO |
LIBERO-Goal / LIBERO-10 |
|
覆盖目标条件和长程 LIBERO 套件。 |
观测与动作#
字段 |
说明 |
|---|---|
Observation |
为 Dexbotic 策略打包的 LIBERO 相机流与本体状态。 |
Action |
选定 Dexbotic 策略后端生成的分块连续动作,包括 flow-matching / flow-SDE 设置。 |
Reward |
PPO 更新使用的 LIBERO 成功信号或仿真器奖励。 |
Prompt |
策略 processor 消费的 LIBERO 自然语言指令。 |
安装#
首先,克隆 RLinf 仓库:
# 为提高国内下载速度,可以使用镜像:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
然后,使用下列两种方式之一准备依赖:预构建的 Docker 镜像(推荐)或自定义环境。
通用的安装流程(前置依赖、GPU 驱动、镜像内置的 switch_env 工具、镜像加速、常见问题排查)
在 安装说明 中统一说明;本方案中的命令仅在 Docker
镜像标签和 --env 取值上有所不同。
选项 1:Docker 镜像 — 镜像标签 agentic-rlinf0.3-maniskill_libero:
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 国内镜像:docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 在容器内切换到 Dexbotic 虚拟环境:
source switch_env dexbotic
选项 2:自定义环境 — 安装 --model dexbotic --env maniskill_libero 依赖组合:
# 国内用户可以添加 --use-mirror 加速下载。
bash requirements/install.sh embodied --model dexbotic --env maniskill_libero
source .venv/bin/activate
下载模型#
下载一个或两个 Dexbotic 检查点(任选一种方式):
# 方法 1:git clone
git lfs install
git clone https://huggingface.co/Dexmal/libero-db-pi0
git clone https://huggingface.co/Dexmal/DM0-libero
# 方法 2:huggingface-hub(国内用户可设置 HF_ENDPOINT=https://hf-mirror.com)
pip install huggingface-hub
huggingface-cli download Dexmal/libero-db-pi0 --local-dir libero-db-pi0
huggingface-cli download Dexmal/DM0-libero --local-dir DM0-libero
下载完成后,在配置 YAML 中指向该检查点——为 rollout 与 actor 两处模型设置相同的路径:
rollout:
model:
model_path: /path/to/downloaded-checkpoint
actor:
model:
model_path: /path/to/downloaded-checkpoint
运行#
每个配方都是 examples/embodiment/config/ 下的一个 YAML 配置:
任务套件 |
模型 |
配置 |
|---|---|---|
LIBERO Spatial |
Dexbotic π₀ |
|
LIBERO Spatial |
DM0 |
|
LIBERO Object |
Dexbotic π₀ |
|
LIBERO Goal |
Dexbotic π₀ |
|
LIBERO 10 |
Dexbotic π₀ |
|
使用 run_embodiment.sh 启动一个配置:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_dexbotic_pi0
这个命令会:
加载
examples/embodiment/config/libero_spatial_ppo_dexbotic_pi0.yaml。按
cluster.component_placement构建 LIBERO actor、rollout 和 env worker。运行 PPO,并把日志和检查点写入
runner.logger.log_path。
独立评测#
对训练后的检查点运行 Dexbotic 的 LIBERO evaluator:
python toolkits/standalone_eval_scripts/dexbotic/libero_eval.py \
--config_name db_pi0_libero \
--pretrained_path /path/to/checkpoint \
--task_suite_name libero_spatial \
--num_trials_per_task 50 \
--action_chunk 5 \
--num_steps 10
如需评估 DM0,切换 evaluator 配置和 action chunk:
python toolkits/standalone_eval_scripts/dexbotic/libero_eval.py \
--config_name dm0_libero \
--pretrained_path /path/to/checkpoint \
--task_suite_name libero_spatial \
--num_trials_per_task 50 \
--action_chunk 10 \
--num_steps 10
也可以使用 RLinf 统一的 VLA 评估流程,详见 评估。
可视化与结果#
启动 TensorBoard 实时观察训练:
tensorboard --logdir ./logs --port 6006
最值得关注的指标是 ``env/success_once`` —— 回合成功率。每个日志指标的含义见 训练指标。