具身智能场景#
具身智能场景包含SOTA模型(如pi0、pi0.5、OpenVLA-OFT)和不同模拟器(如LIBERO、ManiSkill、RoboTwin、MetaWorld)的训练示例,以及真机强化学习训练示例等。
基于ManiSkill的强化学习
ManiSkill+OpenVLA+PPO/GRPO达到SOTA训练效果

基于LIBERO的强化学习
LIBERO+OpenVLA-OFT+GRPO成功率达99%
AMD ROCm 平台上的 LIBERO 强化学习
LIBERO 强化学习的 ROCm 依赖安装与 OSMesa 渲染配置
Ascend CANN 平台上的 LIBERO 强化学习
LIBERO 强化学习的 CANN 依赖安装与驱动挂载配置
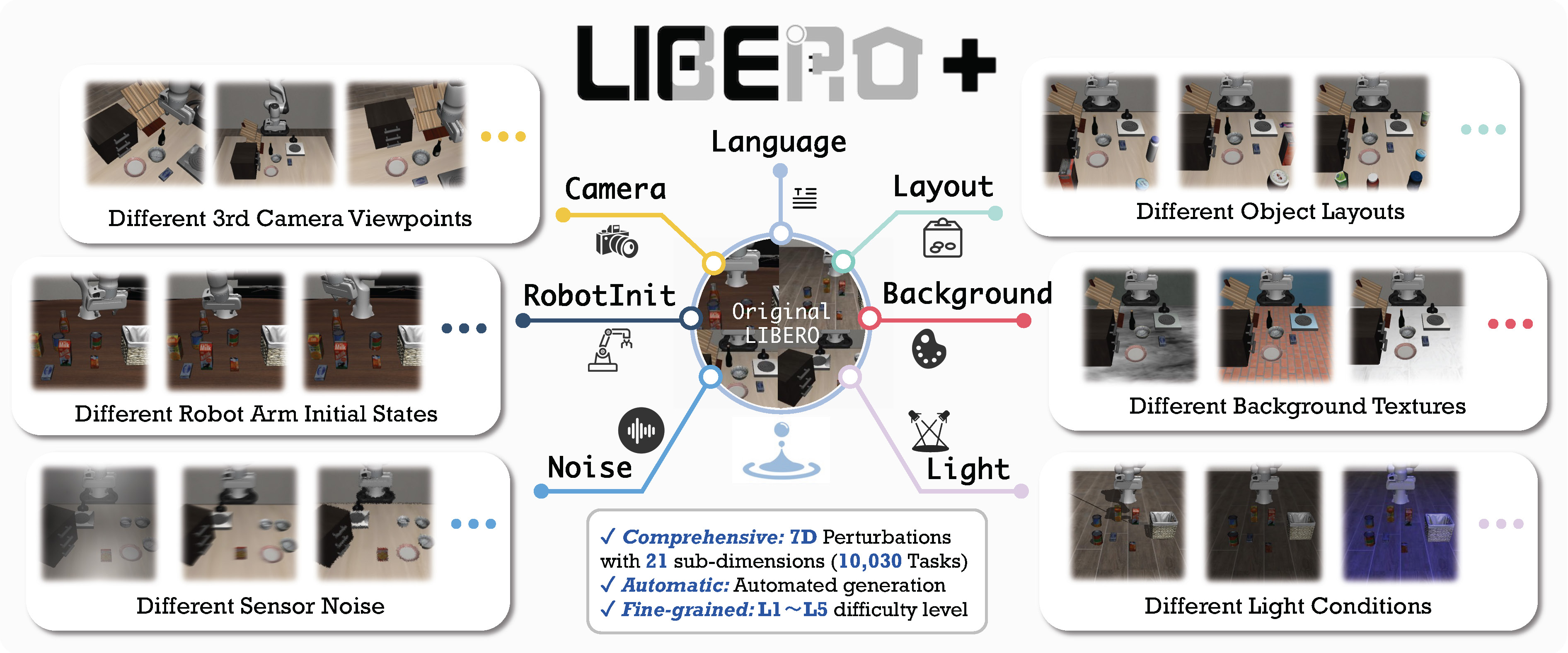
基于 LIBERO-Pro 与 LIBERO-Plus 的强化学习
支持 LIBERO-Pro / LIBERO-Plus + OpenVLA-OFT / π₀ / π₀.₅ + PPO/GRPO 训练

基于Behavior的强化学习
支持Behavior+OpenVLA-OFT+PPO/GRPO训练

基于MetaWorld的强化学习
支持MetaWorld+π₀/π₀.₅+PPO/GRPO训练

基于IsaacLab的强化学习
支持IsaacLab+gr00t+PPO训练

基于CALVIN的强化学习
支持CALVIN+π₀/π₀.₅+PPO/GRPO训练

基于RoboCasa的强化学习
支持RoboCasa+π₀+GRPO训练

基于RoboTwin的强化学习
支持RoboTwin + OpenVLA-OFT/π₀/π₀.₅ + PPO/GRPO训练

基于Franka-Sim的强化学习
支持Franka-Sim+MLP/CNN+PPO/SAC训练

基于 EmbodiChain 的强化学习
使用 EmbodiChain gym 任务进行 MLP + PPO 训练
基于 OpenSora 世界模型的强化学习
支持 OpenSora 世界模型 + OpenVLA-OFT + GRPO 训练

基于 Wan 世界模型的强化学习
支持 Wan 世界模型 + OpenVLA-OFT + GRPO 训练

基于 GSEnv 的 Real2Sim2Real 强化学习
支持 GSEnv + π₀.₅ + PPO 训练

基于 D4RL 基准的离线强化学习
支持 D4RL 场景的 IQL 离线训练
π₀和π₀.₅模型强化学习训练
在π₀和π₀.₅上实现强化学习的效果跃升

GR00T模型强化学习训练
支持GR00T-N1.5与N1.6强化学习微调

基于 Lingbot-VLA 模型的强化学习
支持 Lingbot-VLA + RoboTwin + GRPO 训练
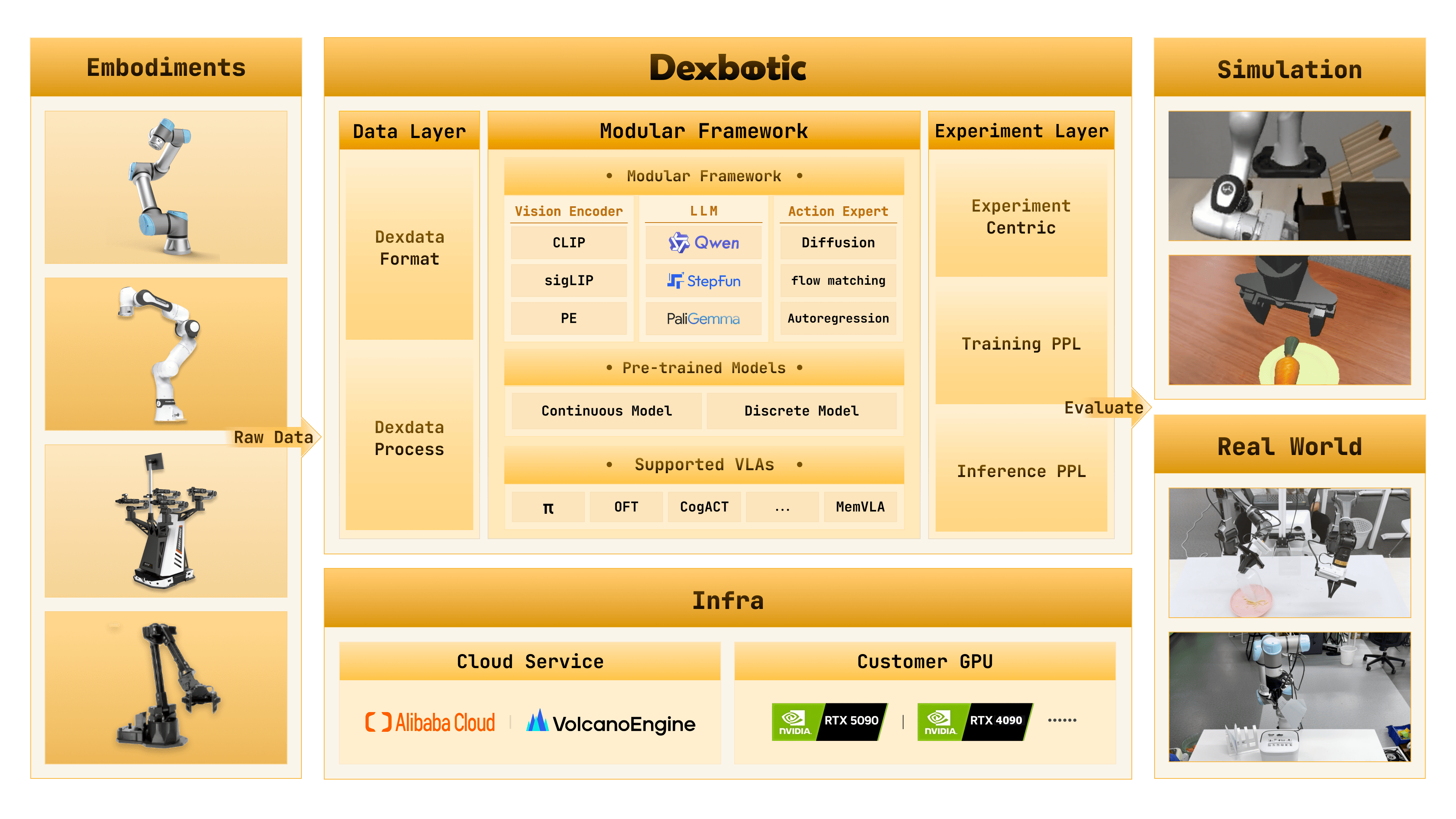
基于 Dexbotic 模型的强化学习训练
Dexbotic(基于 π₀.₅)+ LIBERO + PPO 训练

StarVLA 模型强化学习训练
StarVLA + LIBERO + GRPO 具身强化学习训练

基于RoboVerse的强化学习
支持RoboVerse + π₀.₅ + PPO训练

基于MLP的强化学习
使用 PPO/SAC/GRPO 训练 PPO 策略

SAC-Flow 策略训练
使用 SAC 训练 Flow Matching 策略 (Sim & Real)
监督微调训练
支持 OpenPI 全量 SFT 与 LoRA 微调,作为强化学习前置阶段

VLM模型监督微调训练
支持 Qwen 系列等 VLM 的全量监督微调与结果评估

DSRL:Pi0 噪声空间强化学习
用轻量级 SAC 智能体在噪声空间引导冻结的 Pi0 扩散策略

具身策略的 DAgger 训练
通过专家重标注与回放缓冲区训练推进在线模仿学习

RECAP:离线优势条件策略优化
基于优势引导的离线策略优化

仿真-真机协同训练
仿真 PPO + 真机 SFT,提升 Sim-to-Real 迁移

Franka真机强化学习
RLinf worker无缝对接Franka机械臂

Franka真机强化学习(基于 Reward Model )
使用 reward model 辅助完成机器人操作任务

Franka 真机使用 ZED 相机与 Robotiq 夹爪
Franka 真机中 ZED 相机、Robotiq 夹爪安装与数据采集配置

Franka 真机使用 GELLO 遥操作设备
Franka 真机中 GELLO 遥操作设备安装、配置与验证流程

Franka 机械臂与灵巧手真机强化学习
Franka 机械臂 + 睿研五指灵巧手真机强化学习

Franka 机械臂上的 HG-DAgger
Human-Gated 真机 DAgger 流程:数据采集、SFT 与在线干预训练

GimArm 真机强化学习
GimArm 六自由度机械臂 + peg-insertion 任务,通过 SocketCAN 通信,并基于 Pinocchio 做正运动学
Franka真机Pi0监督微调与部署全流程
数据采集 + Pi0 SFT + 真机部署的完整端到端演示

XSquare Turtle2 真机强化学习
SAC + CNN 策略在 XSquare Turtle2 双臂机器人上的真机训练
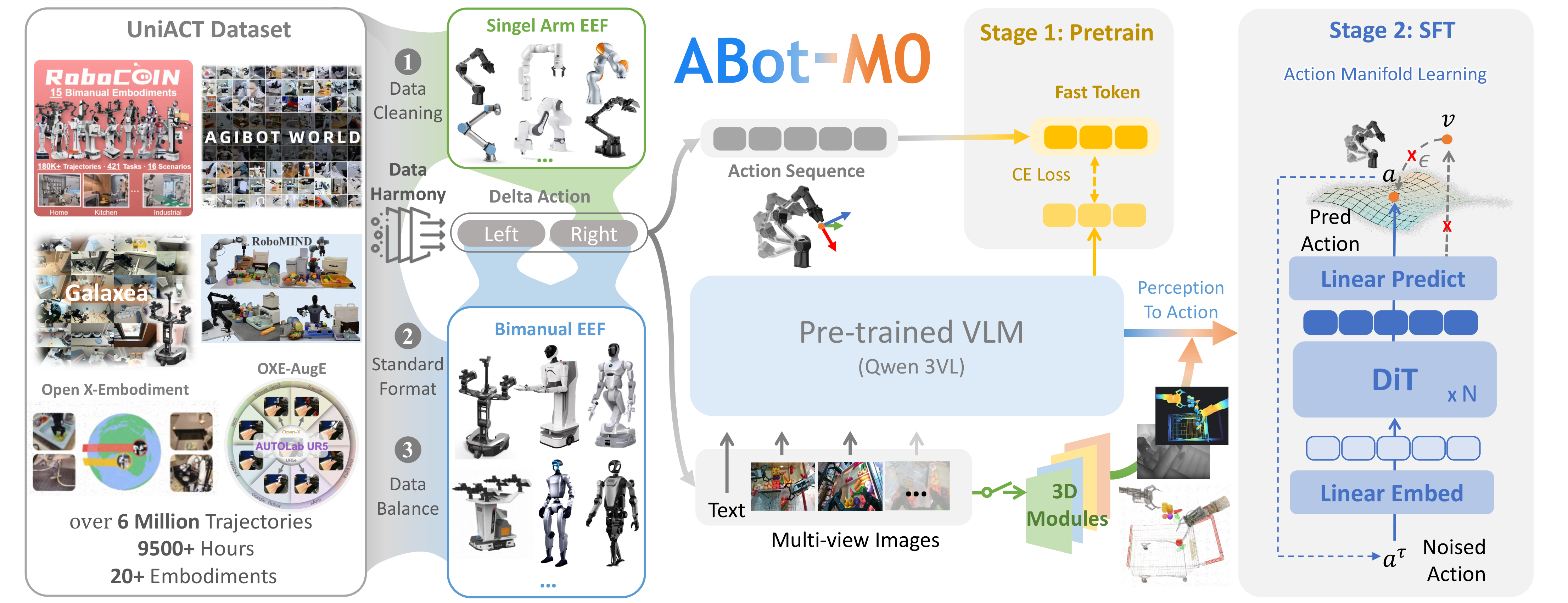
ABot-M0 模型强化学习训练
ABot-M0 原生集成与 LIBERO-plus PPO 训练

Dexmal DOS-W1 真机强化学习
基于 Flow Matching 策略 + SAC 的 Dexmal DOS-W1 双臂抓取任务

GimArm
集成 GimArm 机械臂的数据采集