RECAP:基于离线优势估计的策略优化#
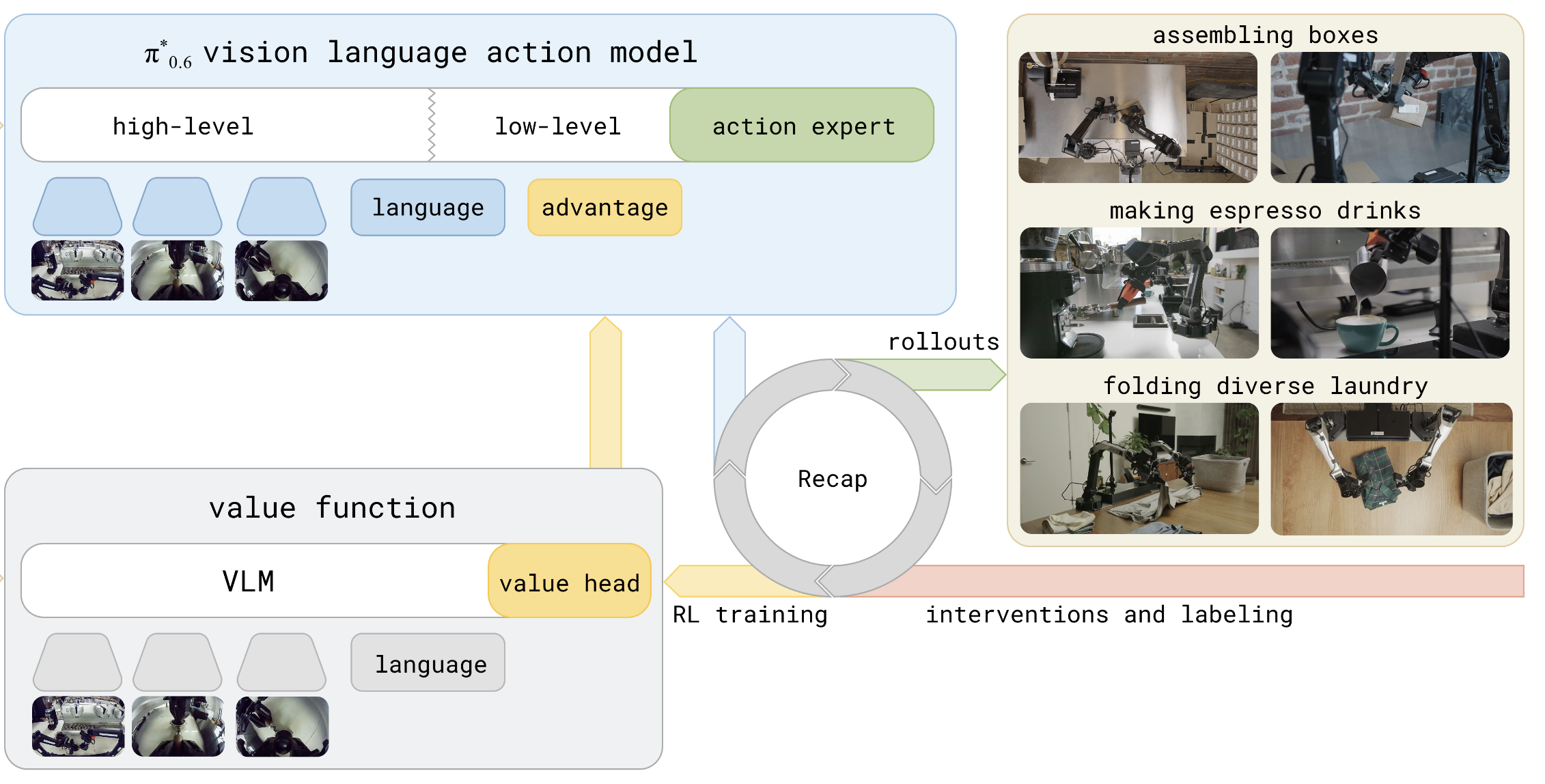
The RECAP offline pipeline.#
使用 RECAP(RL with Experience and Corrections via Advantage-conditioned Policies) 在离线数据上优化策略。RECAP 不需要在线环境交互:先离线计算 return、训练 value model、估计 advantage,再通过 Classifier-Free Guidance(CFG)训练 优化策略,适合真实机器人等难以大规模在线采样的场景。
概览#
离线提升 π₀.₅ 策略(无需新采样):用价值模型为已有数据打分,再以无分类器引导(CFG)进行优化。
RECAP (CFG)
π₀.₅
LeRobot 数据集
离线 · 4 阶段
流程#
RECAP 包含四个顺序执行的阶段:
┌──────────────────────┐ ┌──────────────────────┐ ┌────────────────────────┐ ┌──────────────────────┐
│ Step 1 │ │ Step 2 │ │ Step 3 │ │ Step 4 │
│ Compute Returns │────▶│ Value Model SFT │────▶│ Compute Advantages │────▶│ CFG Training │
└──────────────────────┘ └──────────────────────┘ └────────────────────────┘ └──────────────────────┘
核心思路
Compute Returns:对数据集中的每条轨迹,按 \(G_t = r_t + \gamma \cdot G_{t+1}\) 逆序计算折扣回报,生成 sidecar 文件而不修改原始数据。
Value Model SFT:训练一个价值模型(基于 VLM backbone + Value Head),使其从观察(图像 + 语言指令)预测归一化回报。
Compute Advantages:利用训练好的价值模型,按 \(A_t = \text{normalize}(r_{t:t+N}) + \gamma^N \cdot V(o_{t+N}) - V(o_t)\) 计算每个时间步的优势,并根据分位数阈值将样本标记为正/负。
CFG Training:使用优势标签训练策略模型——正样本(高优势)作为条件输入,负样本(低优势)作为无条件输入,实现 classifier-free guidance 策略优化。
RECAP 工作原理#
RECAP 核心组件
回报计算(Return Computation)
对 SFT 数据集(全部成功轨迹):每步奖励 \(r_t = -1\),终止步 \(r_T = 0\)
对 rollout 数据集(含失败轨迹):失败轨迹终止步 \(r_T = r_{\text{fail}}\)(如 \(-300\))
折扣因子 \(\gamma\) 默认为 \(1.0\)(无折扣)
价值模型(Value Model)
基于 SigLIP2 视觉编码器 + Gemma3 语言模型 + 可学习 Critic Expert
采用分布式价值预测(Categorical Value Distribution),默认 201 个 bin
输出范围 \([-1, 0]\)(归一化后的回报空间)
优势估计(Advantage Estimation)
N 步前瞻优势:\(A_t = \text{normalize}(r_{t:t+N}) + \gamma^N \cdot V(o_{t+N}) - V(o_t)\)
分位数阈值:top \(X\%\) 的样本标记为正样本(默认 \(X = 30\))
支持多 GPU 分布式推理
Classifier-Free Guidance(CFG)训练
基于 OpenPI (pi0.5) 策略模型
positive_only_conditional模式:仅正样本作为条件输入,负样本一律无条件正样本以
unconditional_prob概率随机转为无条件(默认 \(0.1\)),实现 dropout 正则化推理时通过
cfgrl_guidance_scale控制引导强度
安装#
1. 克隆 RLinf 仓库#
# 为提高国内下载速度,可以使用:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
2. 安装依赖#
方式一:Docker 镜像
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 为提高国内下载速度,可以使用:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
进入容器后,切换到 OpenPI 虚拟环境:
source switch_env openpi
方式二:自建环境
# 为提高国内依赖安装速度,可以添加`--use-mirror`到下面的install.sh命令
bash requirements/install.sh embodied --model openpi --env maniskill_libero
source .venv/bin/activate
下载模型#
RECAP 流程需要以下预训练模型:
SigLIP2-so400m:视觉编码器,用于 Step 2 价值模型训练
Gemma3-270M:语言模型,用于 Step 2 价值模型训练
pi0.5 base (PyTorch):策略模型,用于 Step 4 CFG 训练。请参考 openpi 获取模型权重并转换为 PyTorch 格式
Step 2 所需模型下载
# 下载模型(选择任一方法)
# 方法 1: 使用 git clone
git lfs install
git clone https://huggingface.co/google/siglip2-so400m-patch14-224
git clone https://huggingface.co/google/gemma-3-270m
# 方法 2: 使用 huggingface-hub
# 为提升国内下载速度,可以设置:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download google/siglip2-so400m-patch14-224 --local-dir siglip2-so400m-patch14-224
hf download google/gemma-3-270m --local-dir gemma-3-270m
下载完成后,请在配置文件中正确指定模型路径:
# Step 2 价值模型配置
actor:
model:
siglip_path: /path/to/siglip2-so400m-patch14-224
gemma3_path: /path/to/gemma-3-270m
tokenizer_path: /path/to/gemma-3-270m
# Step 4 策略模型配置
actor:
model:
model_path: /path/to/pi05_base_pytorch
数据准备#
RECAP 流程使用 LeRobot 格式的数据集。数据集分为两类:
SFT 数据集:来自人类演示或已训练策略的成功轨迹
Rollout 数据集:在线交互采集的轨迹,包含成功和失败
数据集配置示例:
data:
train_data_paths:
- dataset_path: /path/to/sft_dataset
type: sft # 全部成功轨迹
weight: 1.0
- dataset_path: /path/to/rollout_dataset
type: rollout # 含失败轨迹
weight: 1.0
备注
train_data_paths 是一个列表。如果需要混合多个数据集,可以继续新增 item;如果只想使用单个数据集训练,也可以只保留一个 item。
所有 step 中的 train_data_paths 应保持一致,确保回报、价值和优势的计算基于同一批数据。
Pipeline Tag 机制#
RECAP 通过 tag 实现各步骤之间的数据传递和版本管理:
returns_tag:Step 1 生成,Step 2 和 Step 3 读取。请确保 Step 1 的
data.tag、Step 2 的data.tag和 Step 3 的advantage.returns_tag保持一致。advantage_tag:Step 3 生成,Step 4 读取。请确保 Step 3 的
advantage.tag和 Step 4 的data.advantage_tag保持一致。
Step |
配置字段 |
说明 |
|---|---|---|
1 |
|
写入 |
2 |
|
读取 |
3 |
|
读取 |
3 |
|
写入 |
4 |
|
读取 |
Step 1:计算回报(Compute Returns)#
本步骤对数据集中每条轨迹逆序计算折扣累积回报,结果以 sidecar 文件形式保存,不修改原始数据。
配置文件
配置文件位于 examples/offline_rl/config/recap_compute_returns.yaml:
data:
train_data_paths:
- dataset_path: /path/to/sft_dataset
type: sft
- dataset_path: /path/to/rollout_dataset
type: rollout
gamma: 1.0 # 折扣因子
failure_reward: -300.0 # 失败轨迹终止奖励
tag: "fail300" # 输出文件标签
num_workers: 128 # 并行处理线程数
关键参数
参数 |
默认值 |
说明 |
|---|---|---|
|
|
折扣因子。\(1.0\) 表示无折扣,即简单累加未来奖励 |
|
|
失败轨迹终止步的惩罚值。值越大(绝对值),成功/失败的回报区分度越高 |
|
|
输出文件标签,生成 |
|
|
并行处理 parquet 文件的线程数 |
启动命令
bash examples/offline_rl/advantage_labeling/recap/process/run_compute_returns.sh recap_compute_returns
输出文件
meta/returns_{tag}.parquet:每行包含episode_index、frame_index、return、reward、promptmeta/stats.json:更新回报统计信息(均值、标准差、最小值、最大值)
验证方法
python3 -c "
import json
stats = json.load(open('/path/to/dataset/meta/stats.json'))
assert 'return' in stats
print('return stats:', stats['return'])
"
Step 2:训练价值模型(Value Model SFT)#
使用 Step 1 计算的回报作为监督信号,训练价值模型学习从观察(图像 + 语言指令)预测归一化回报。
模型架构
价值模型由三部分组成:
视觉编码器:SigLIP2-so400m(1152 维)—— 处理 RGB 图像输入
语言模型:Gemma3-270M(640 维)—— 处理语言指令
Critic Expert:可学习专家头,将多模态表征映射到价值预测
输出为分类分布(Categorical Value Distribution),覆盖 \([-1, 0]\) 区间的 201 个 bin。
配置文件
配置文件位于 examples/offline_rl/config/recap_value_model_sft.yaml,核心字段如下:
data:
train_data_paths:
- dataset_path: /path/to/sft_dataset
type: sft
weight: 1.0
robot_type: "libero"
model_type: "pi05"
tag: "fail300" # 对应 Step 1 的 tag
action_horizon: 10
normalize_to_minus_one_zero: true # 归一化到 [-1, 0]
eval_data_paths: # 可选,推荐配置
- dataset_path: /path/to/eval_dataset
max_samples: 10000
robot_type: "libero"
model_type: "pi05"
actor:
micro_batch_size: 32
global_batch_size: 256
model:
freeze_vlm: false # 是否冻结 VLM backbone
value_dropout: 0.0 # Value Head dropout
optim:
lr: 5.0e-5 # VLM backbone 学习率
value_lr: 1.0e-4 # Value Head 学习率
weight_decay: 1.0e-10
lr_warmup_steps: 500
runner:
max_epochs: 30000
save_interval: 3000 # checkpoint 保存间隔
关键参数
参数 |
默认值 |
说明 |
|---|---|---|
|
|
与 Step 1 相同的 tag,用于读取对应的 |
|
|
归一化模式。 |
|
|
冻结视觉编码器。设为 |
|
|
Value Head 前的 dropout 率 |
|
|
VLM backbone 学习率 |
|
|
Value Head 学习率 |
启动命令
训练脚本会自动初始化 Ray 集群:
bash examples/offline_rl/advantage_labeling/recap/run_value_sft.sh recap_value_model_sft
输出
模型 checkpoint 保存在
logs/value_sft/{config_name}-{timestamp}/value_sft/checkpoints/TensorBoard 日志
关键监控指标
train/actor/loss:价值模型的总训练损失train/actor/grad_norm:梯度范数eval/spearman_correlation:Spearman 相关系数,衡量预测值与真实回报的排序一致性
备注
训练完成后,需要记录 checkpoint 路径用于 Step 3。Checkpoint 位于:
logs/value_sft/{config_name}-{timestamp}/value_sft/checkpoints/global_step_{N}/actor/model_state_dict
Step 3:计算优势(Compute Advantages)#
使用 Step 2 训练好的价值模型,对数据集中每个时间步计算优势值,并根据分位数阈值将样本标记为正/负。
优势计算公式
其中 \(N\) 为前瞻步数(advantage_lookahead_step),\(\gamma\) 为折扣因子。
配置文件
配置文件位于 examples/offline_rl/config/recap_compute_advantages.yaml:
advantage:
value_checkpoint: /path/to/value_checkpoint
positive_quantile: 0.3 # top 30% 标记为正样本
tag: "fail300_N10_ckpt18000_q30"
returns_tag: "fail300" # 对应 Step 1 的 tag
batch_size: 1024
data:
train_data_paths:
- dataset_path: /path/to/sft_dataset
robot_type: "libero"
type: "sft"
weight: 1.0
advantage_lookahead_step: 10 # N 步前瞻
gamma: 1.0
关键参数
参数 |
默认值 |
说明 |
|---|---|---|
|
必填 |
Step 2 训练好的价值模型 checkpoint 路径 |
|
|
正样本比例。\(0.3\) 表示优势值 top 30% 的样本标记为正 |
|
|
前瞻步数 \(N\),即考虑未来多少步的奖励 |
|
|
读取 Step 1 生成的回报文件标签 |
|
|
输出优势文件标签,生成 |
启动命令
支持多 GPU 分布式推理:
bash examples/offline_rl/advantage_labeling/recap/process/run_compute_advantages.sh recap_compute_advantages
输出文件
meta/advantages_{tag}.parquet:包含advantage(布尔)、advantage_continuous(浮点)等列更新
mixture_config.yaml:记录全局阈值和归一化统计
验证方法
python3 -c "
import pandas as pd
df = pd.read_parquet('/path/to/dataset/meta/advantages_fail300_N10_ckpt18000_q30.parquet')
print(f'samples={len(df)}, columns={list(df.columns)}')
print(df[['advantage_continuous']].describe())
"
Step 4:CFG Training#
使用 Step 3 计算的优势标签,对 OpenPI 策略模型进行 classifier-free guidance 训练。
训练机制
正样本(
advantage=True):作为条件输入传入模型负样本(
advantage=False):作为无条件输入传入模型当
positive_only_conditional开启时,正样本以unconditional_prob概率随机 dropout 为无条件,实现正则化推理时通过引导尺度
cfgrl_guidance_scale放大正负样本之间的差异,引导模型生成高优势动作
配置文件
配置文件位于 examples/offline_rl/config/cfg_rl_openpi.yaml:
data:
advantage_tag: "fail300_N10_ckpt18000_q30" # 对应 Step 3 的 advantage.tag
balance_dataset_weights: true
train_data_paths:
- dataset_path: /path/to/sft_dataset
type: sft
weight: 1.0
- dataset_path: /path/to/rollout_dataset
type: rollout
weight: 1.0
actor:
micro_batch_size: 32
global_batch_size: 512
model:
model_path: /path/to/pi05_base_pytorch
openpi:
config_name: "pi05_libero"
positive_only_conditional: true
unconditional_prob: 0.1
cfgrl_guidance_scale: 1.0
optim:
lr: 1.0e-5
lr_scheduler: cosine
lr_warmup_steps: 5000
total_training_steps: 30000
关键参数
参数 |
默认值 |
说明 |
|---|---|---|
|
|
对应 Step 3 的 |
|
|
仅正样本做条件输入。 |
|
|
样本 dropout 为无条件的概率。 |
|
|
推理时的引导尺度。越大越偏向高优势动作 |
|
|
数据变换配置。LIBERO 用 |
|
|
按数据集大小平衡采样权重 |
启动命令
bash examples/offline_rl/policy_optimization/cfg_rl/run_cfg_rl.sh cfg_rl_openpi
关键监控指标
train/actor/loss:策略训练损失train/actor/grad_norm:梯度范数
可视化优势分布#
Step 3 完成后,可以使用 examples/offline_rl/advantage_labeling/recap/process/visualize_advantage_dataset.py 对优势分布进行可视化分析,
包括优势直方图、价值预测分布、逐 episode 正样本率等统计图,以及带优势标注的 episode 回放视频。
基本用法
生成分布图和 episode 视频:
python examples/offline_rl/advantage_labeling/recap/process/visualize_advantage_dataset.py \
--dataset /path/to/your/dataset \
--output outputs/advantage_viz \
--tag "fail300_N10_ckpt18000_q30" \
--num-episodes 10
仅生成分布图(不生成视频):
python examples/offline_rl/advantage_labeling/recap/process/visualize_advantage_dataset.py \
--dataset /path/to/your/dataset \
--output outputs/advantage_viz \
--tag "fail300_N10_ckpt18000_q30" \
--no-video
指定 episode 可视化:
python examples/offline_rl/advantage_labeling/recap/process/visualize_advantage_dataset.py \
--dataset /path/to/your/dataset \
--output outputs/advantage_viz \
--tag "fail300_N10_ckpt18000_q30" \
--episodes 0 5 10 20
关键参数
参数 |
默认值 |
说明 |
|---|---|---|
|
必填 |
LeRobot 数据集路径 |
|
|
输出目录 |
|
|
优势文件标签,读取 |
|
|
可视化的 episode 数量( |
|
|
指定要可视化的 episode 索引列表 |
|
|
跳过视频生成,仅输出静态图 |
|
自动检测 |
优势阈值。未设置时自动从 |
输出内容
advantage_distribution.png:6 子图的综合统计面板(优势直方图、价值分布、散点图、逐 episode 正样本率、逐 episode 优势均值、统计摘要)episode_{N}_summary.png:每个 episode 的关键帧 + 价值/优势时序图(高于阈值的帧用绿色边框标注)episode_{N}.mp4:带优势标注的逐帧回放视频
运行#
按照上面的 RECAP 阶段依次计算 return、训练价值模型、计算 advantage,并训练 CFG policy。
可视化与结果#
指标含义见 训练指标。
TensorBoard 日志
tensorboard --logdir ./logs --port 6006
RECAP 流程会在 logs/ 目录下生成两个子目录:
logs/value_sft/:价值模型训练日志(Step 2)logs/cfg_sft/:CFG 策略训练日志(Step 4)
训练日志工具集成
runner:
logger:
log_path: "../results"
project_name: rlinf
experiment_name: "recap_experiment"
logger_backends: ["tensorboard"] # 也支持 wandb, swanlab
数据集#
我们在 LIBERO-10 基准(Task 0)上提供了可复现的实验,演示完整的 RECAP 流程。
SFT 数据:LIBERO-10 的专家演示数据(成功轨迹)
Rollout 数据:few-shot π0.5 策略在 Task 0 上采集的 4,096 条轨迹,包含成功和失败的 episode
Eval 数据:同样由 few-shot π0.5 策略采集的验证集,用于 Step 2 监控价值模型是否过拟合
备注
本页有意使用初始成功率适中的 few-shot π0.5 策略,以便在紧凑的 Task 0 示例中观察 RECAP 的离线提升。下方 baseline 仅对应该可复现实验设置, 不代表 π0.5 SFT 在完整 LIBERO benchmark 上的通用表现。
数据集可从 此处 下载。
RECAP 实验结果#
在 LIBERO-10 Task 0 上执行一轮 RECAP 迭代后,成功率从 48.8%(本页设置下的 few-shot SFT baseline)提升至 66.5%(RECAP),绝对提升 17.7%。
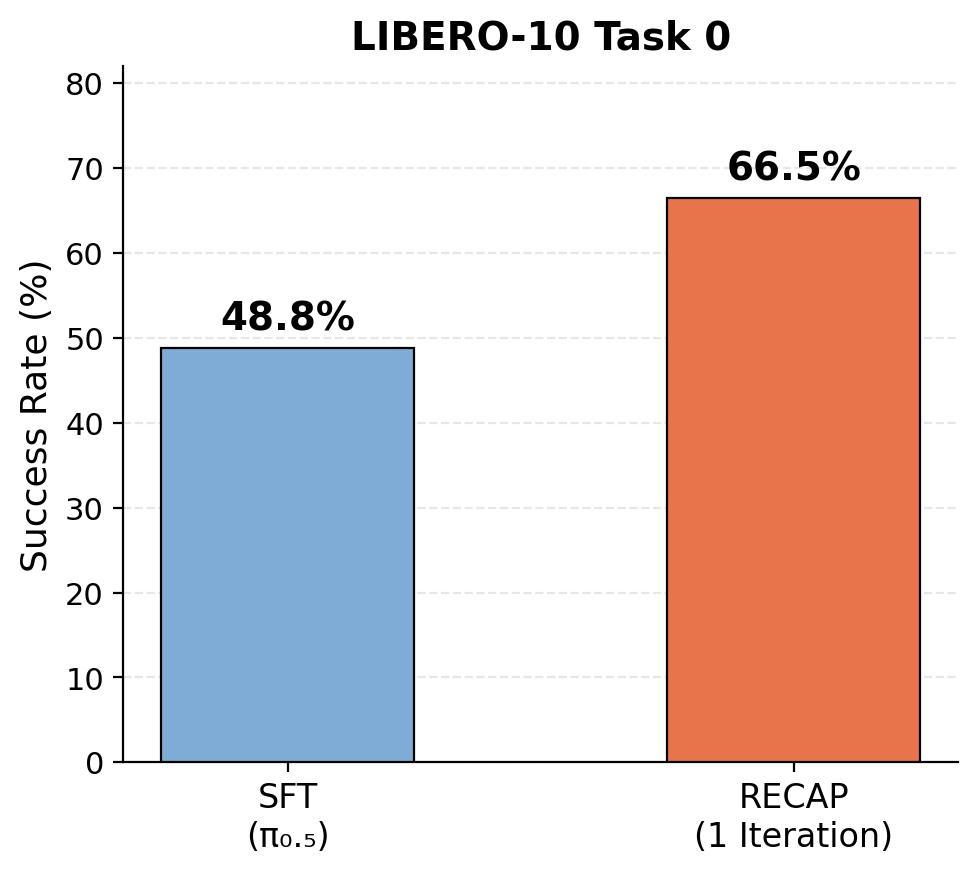
LIBERO-10 Task 0 上的 RECAP 实验结果
高级用法#
优势阈值重标#
如果需要修改分位数阈值(如从 30% 调整为 20%),无需重新运行完整的 Step 3。
可以使用 relabel_advantages.py 仅重标阈值:
cd examples/offline_rl/advantage_labeling/recap/process
python relabel_advantages.py \
--dataset_paths /path/to/sft_dataset /path/to/rollout_dataset \
--source_tag "fail300_N10_ckpt18000_q30" \
--new_tag "fail300_N10_ckpt18000_q20" \
--positive_quantile 0.2
也可以使用 --dataset_root 指定包含多个数据集的根目录,配合 --advantage_lookahead_step 重算优势:
python relabel_advantages.py \
--dataset_root /path/to/dataset_root \
--advantage_lookahead_step 20 \
--positive_quantile 0.3
该脚本会读取已有的连续优势值(advantage_continuous),仅更新阈值和布尔标签,避免重复的 GPU 推理。
迭代优化#
RECAP 支持迭代优化:使用 Step 4 训练的策略模型采集新数据,然后从 Step 1 重新开始。 每一轮可以使用不同的 tag 来区分不同迭代的结果:
Iter 1: tag="fail300" → 训练 Value Model → tag="fail300_N10_ckpt18000_q30" → CFG Training
Iter 2: tag="fail300_iter2" → 训练 Value Model → tag="fail300_iter2_N10_ckpt6000_q20" → CFG Training
文件结构#
examples/offline_rl/
├── config/ # 共享生产配置
│ ├── recap_compute_returns.yaml # Step 1
│ ├── recap_value_model_sft.yaml # Step 2
│ ├── recap_compute_advantages.yaml # Step 3
│ ├── cfg_rl_openpi.yaml # Step 4
│ └── model/
│ └── recap_value_model.yaml # 价值模型架构默认配置
├── advantage_labeling/
│ └── recap/
│ ├── train_value.py # Step 2: 训练价值模型
│ ├── run_value_sft.sh # Step 2 启动脚本
│ └── process/
│ ├── compute_returns.py # Step 1:回报逻辑 + Hydra 入口
│ ├── compute_advantages.py # Step 3:优势逻辑 + Hydra 入口
│ ├── relabel_advantages.py # 阈值重标(CPU)
│ ├── visualize_advantage_dataset.py # 优势可视化
│ ├── run_compute_returns.sh # Step 1 启动脚本
│ └── run_compute_advantages.sh # Step 3 启动脚本
└── policy_optimization/
└── cfg_rl/
├── train_cfg.py # Step 4: CFG 策略训练
└── run_cfg_rl.sh # Step 4 启动脚本
rlinf/
├── models/embodiment/value_model/recap/ # 价值评论器、配置、checkpoint 工具
├── data/datasets/recap/ # value_dataset.py、cfg_model.py 等
└── data/process/ # 共享、模型无关(RECAP + STEAM)
├── advantage.py # 分位数阈值 + 布尔标签
├── distributed.py # 分片推理辅助
└── mixture_config.py # meta/mixture_config.yaml tag I/O