VLM 监督微调#
Qwen2.5-VL 在 Robo2VLM 视觉问答数据集上的监督微调。#
使用 RLinf 对视觉-语言模型(Qwen2.5-VL、Qwen3-VL、Qwen3-VL-MoE)进行 全量监督微调 (Full-parameter SFT)——训练、评估,并将得到的检查点转换为 HuggingFace 格式。
概览#
在 Robo2VLM 视觉问答数据集上对 Qwen-VL 系列模型进行全量 SFT,使用 FSDP 并内置评估。
Qwen2.5-VL · Qwen3-VL · Qwen3-VL-MoE
Full-parameter SFT
Robo2VLM (visual QA)
1–2 节点 · GPU
run_vlm_sft.sh → 观察 loss 与评估准确率。本示例主要关注两个文件——启动脚本 examples/sft/run_vlm_sft.sh 和训练配置
examples/sft/config/qwen2_5_vl_sft_vlm.yaml。
安装#
拉取 RLinf 镜像:
rlinf/rlinf:agentic-rlinf0.3-torch2.6.0-sglang0.4.6.post5-vllm0.8.5-megatron0.13.0-te2.1。下载模型权重: Qwen2.5-VL-3B-Instruct。
下载数据集: Robo2VLM-1。
修改
examples/sft/config/qwen2_5_vl_sft_vlm.yaml,并运行examples/sft/run_vlm_sft.sh。
警告
Robo2VLM 下载后会把 train 与 evaluate 数据放在同一目录(如
train-00000-of-00262.parquet 与 test-0000X-of-00003.parquet)。请将它们分到不同文件夹,
否则 RLinf 会直接读取整个数据集。
备注
如需训练 qwen3_vl 或 qwen3_vl_moe,请确保 transformers >= 4.57.1。
运行#
1. 配置
启动脚本默认使用 examples/sft/config/qwen2_5_vl_sft_vlm.yaml,日志重定向到
<repo>/logs/<timestamp>/。实际执行命令为:
python examples/sft/train_vlm_sft.py \
--config-path examples/sft/config/ \
--config-name <你的配置名> \
runner.logger.log_path=<自动生成的日志目录>
VLM 配置与 RLinf 中其他训练配置结构基本一致,主要修改 data 和 actor.model。
下面样例中需要修改的字段已注释,其余参数保持不变即可得到基线运行。
defaults:
- override hydra/job_logging: stdout
hydra:
run:
dir: .
output_subdir: null
cluster:
num_nodes: 1
component_placement:
actor: all
runner:
task_type: sft
logger:
log_path: "../results"
project_name: rlinf
experiment_name: "qwen2_5_vl_sft_demo"
logger_backends: ["tensorboard"]
max_epochs: 6000
max_steps: -1
val_check_interval: 1000
save_interval: 1000
data:
type: vlm
dataset_name: "robo2vlmsft"
# 数据路径,需要将 train 数据和 evaluate 数据分开,并分别放在不同的文件夹下
train_data_paths: "/path/to/Robo2VLM-1/train_data"
# 如果不需要进行训练,只需要进行评估,请将 train_data_paths 设置为 null
val_data_paths: "/path/to/Robo2VLM-1/test_data"
# 数据字段名(要和你的数据列一致)
prompt_key: "question"
choice_key: "choices"
answer_key: "correct_answer"
image_keys: ["image"]
apply_chat_template: True
use_chat_template: True
max_prompt_length: 1024
lazy_loading: false
num_workers: 4
algorithm:
adv_type: gae
actor:
group_name: "ActorGroup"
training_backend: "fsdp"
micro_batch_size: 4
eval_batch_size: 4
global_batch_size: 256
seed: 42
model:
model_type: "qwen2.5_vl"
precision: fp32
# 模型路径,需要将模型权重下载后放在本地,并设置为模型路径
model_path: "/path/to/Qwen2.5-VL-3B-Instruct"
is_lora: False
optim:
lr: 1e-5
adam_beta1: 0.9
adam_beta2: 0.999
adam_eps: 1.0e-08
weight_decay: 0.01
clip_grad: 1.0
lr_scheduler: "cosine"
total_training_steps: ${runner.max_epochs}
lr_warmup_steps: 200
fsdp_config:
strategy: "fsdp"
sharding_strategy: "no_shard"
use_orig_params: False
gradient_checkpointing: False
mixed_precision:
param_dtype: bf16
reduce_dtype: fp32
buffer_dtype: bf16
reward:
use_reward_model: False
critic:
use_critic_model: False
2. 启动
在仓库根目录执行:
bash examples/sft/run_vlm_sft.sh
不传参数时,脚本默认使用
qwen2_5_sft_vlm。若配置文件名不同(如
my_vlm_config.yaml),将其作为参数传入:bash examples/sft/run_vlm_sft.sh my_vlm_config。
仅评估模式#
若只想运行评估,将 data.train_data_paths 设为 null,并将 data.val_data_paths
指向验证数据,启动命令保持不变:
bash examples/sft/run_vlm_sft.sh <配置名>
可视化与结果#
正常的训练中,loss 下降、评估准确率 上升。脚本会自动创建 logs/<时间戳>;可用
TensorBoard 可视化。各项指标的含义见
训练指标。
tensorboard --logdir /path/to/RLinf/logs --port 6006
# 浏览器打开 http://localhost:6006
不同规模模型的参考结果:
模型 |
硬件 |
迭代数 |
评估准确率(训练前 → 训练后) |
|---|---|---|---|
Qwen2.5-VL-3B |
8 × H100 |
6000 |
— → 89.96% |
Qwen3-VL-4B |
4 × H100 |
6000 |
— → 96.9% |
Qwen3-VL-30B-A3B(MoE) |
2 × 8 × A100 |
1000 |
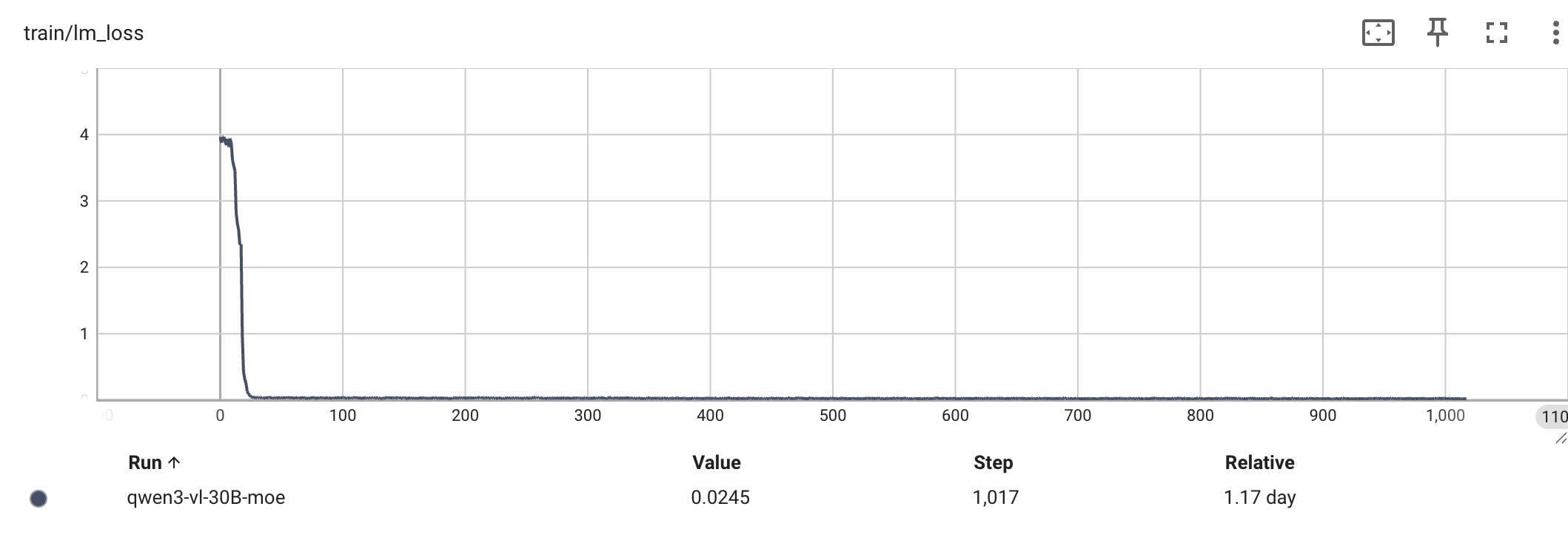
58.4% → 91.3% |
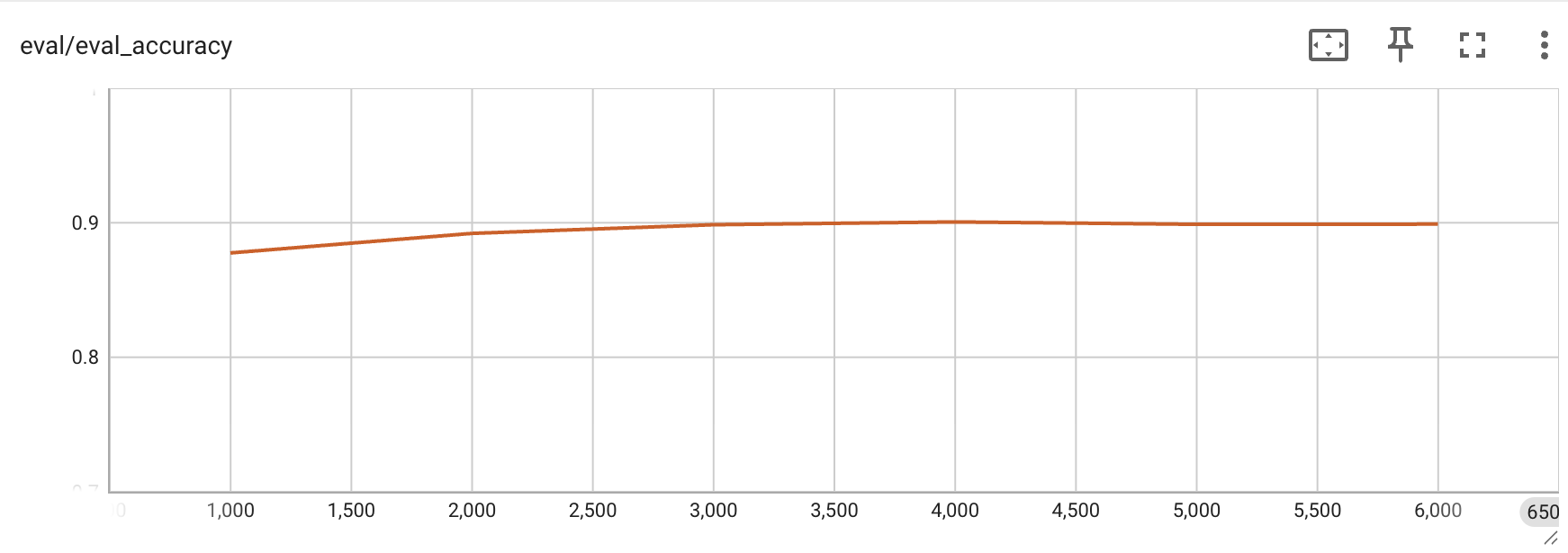
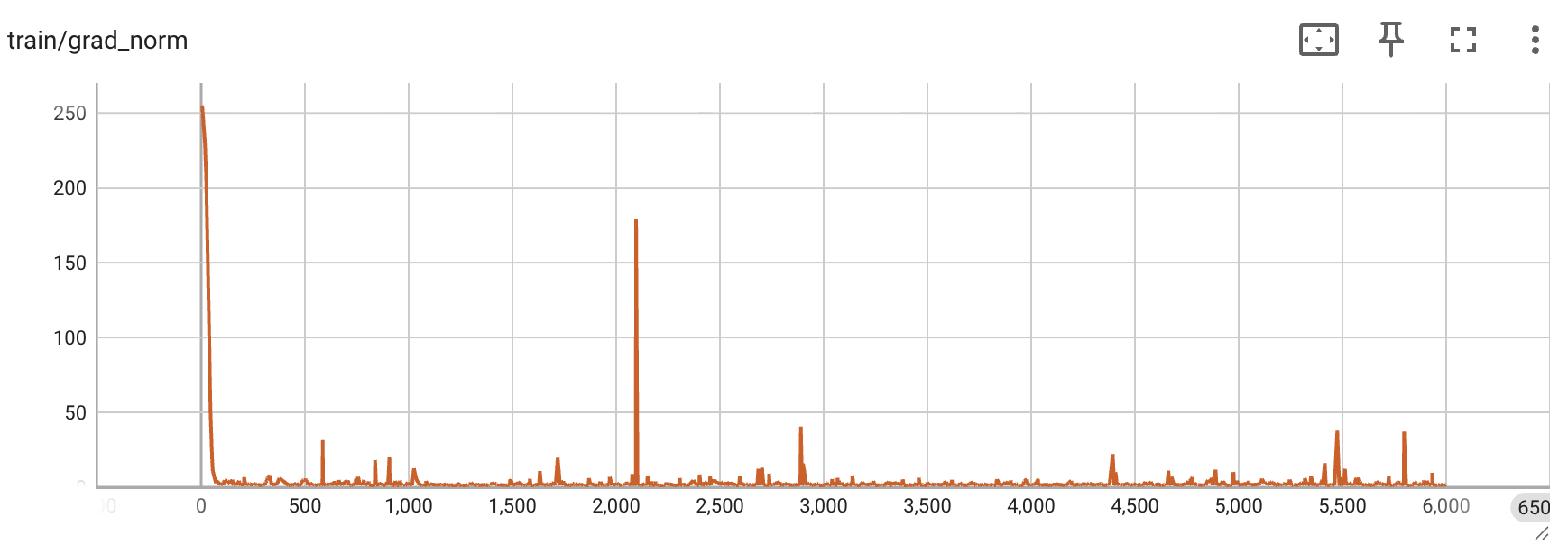
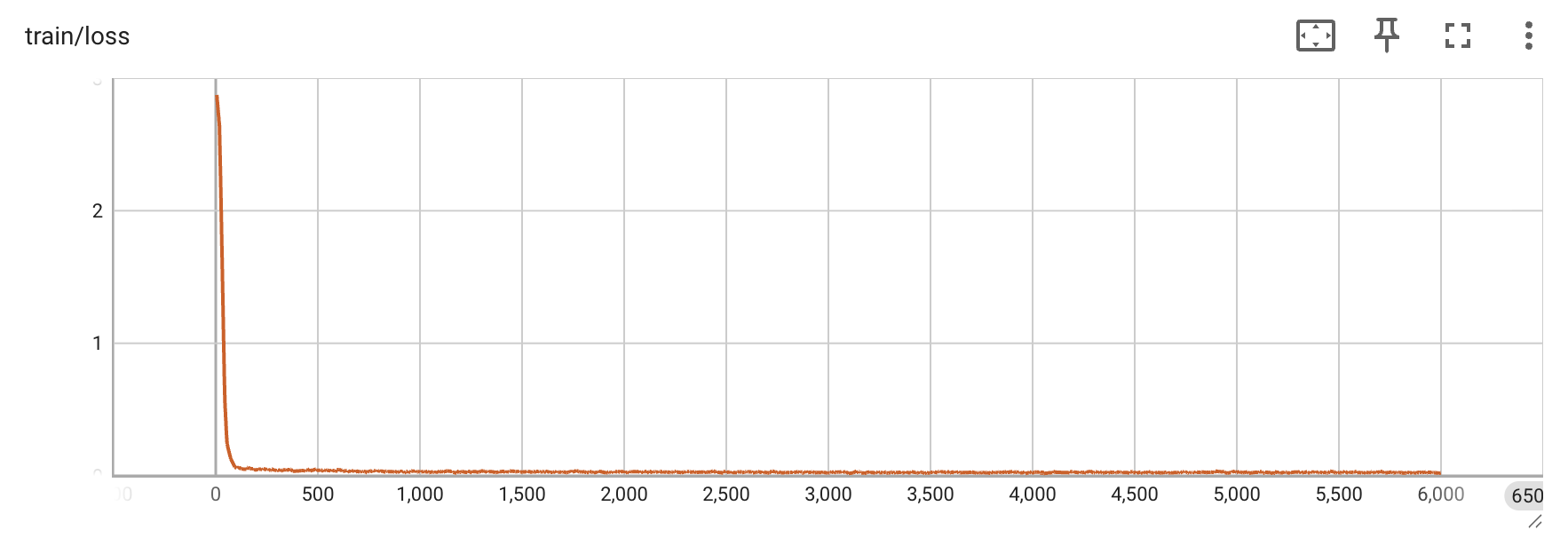
Qwen2.5-VL-3B —— 每 1000 次迭代的评估准确率、grad_norm 与 loss 曲线:
Qwen3-VL-4B —— 每 1000 次迭代的评估准确率、grad_norm 与 loss 曲线:
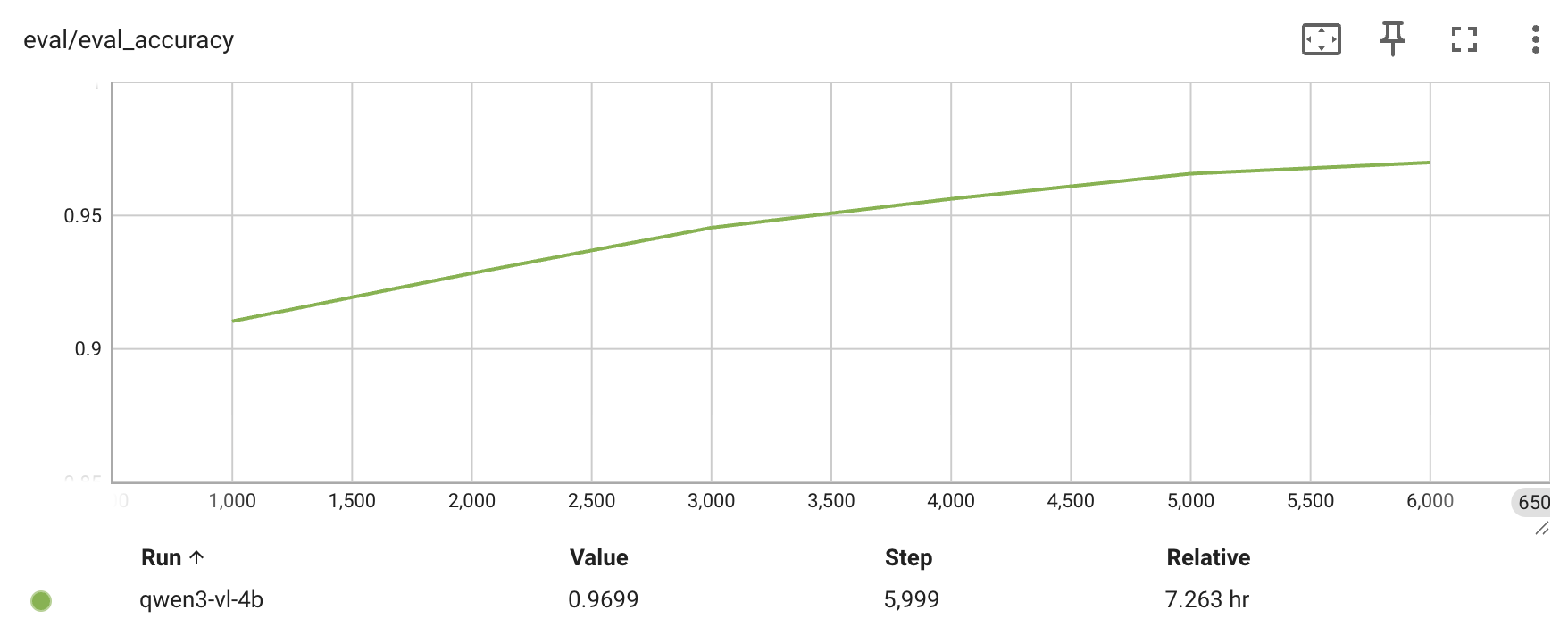
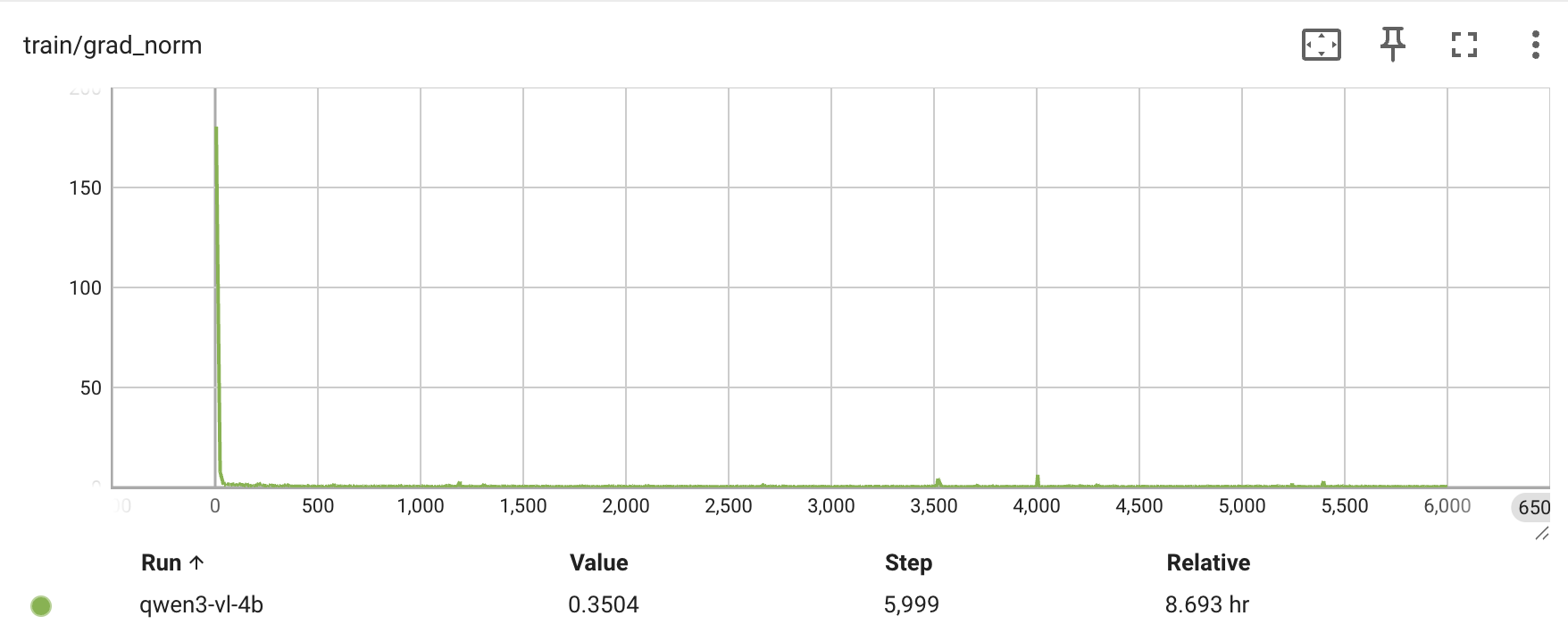
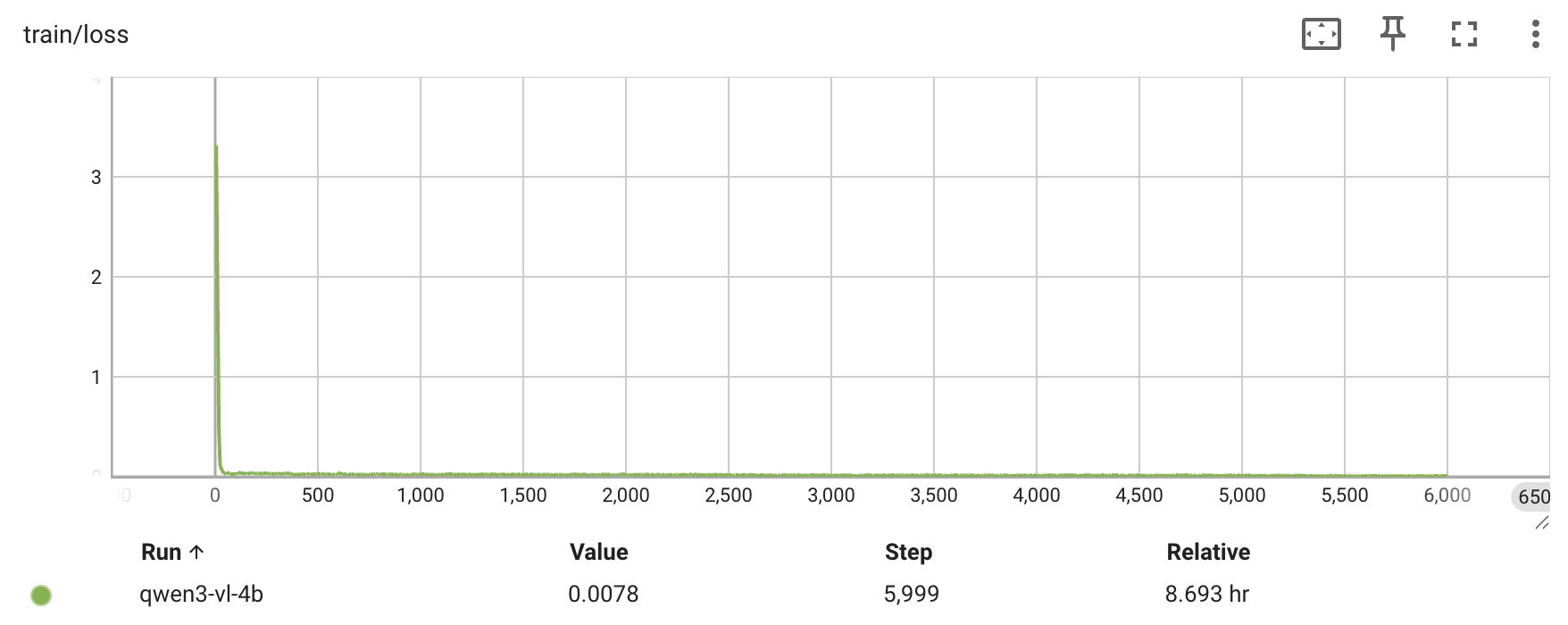
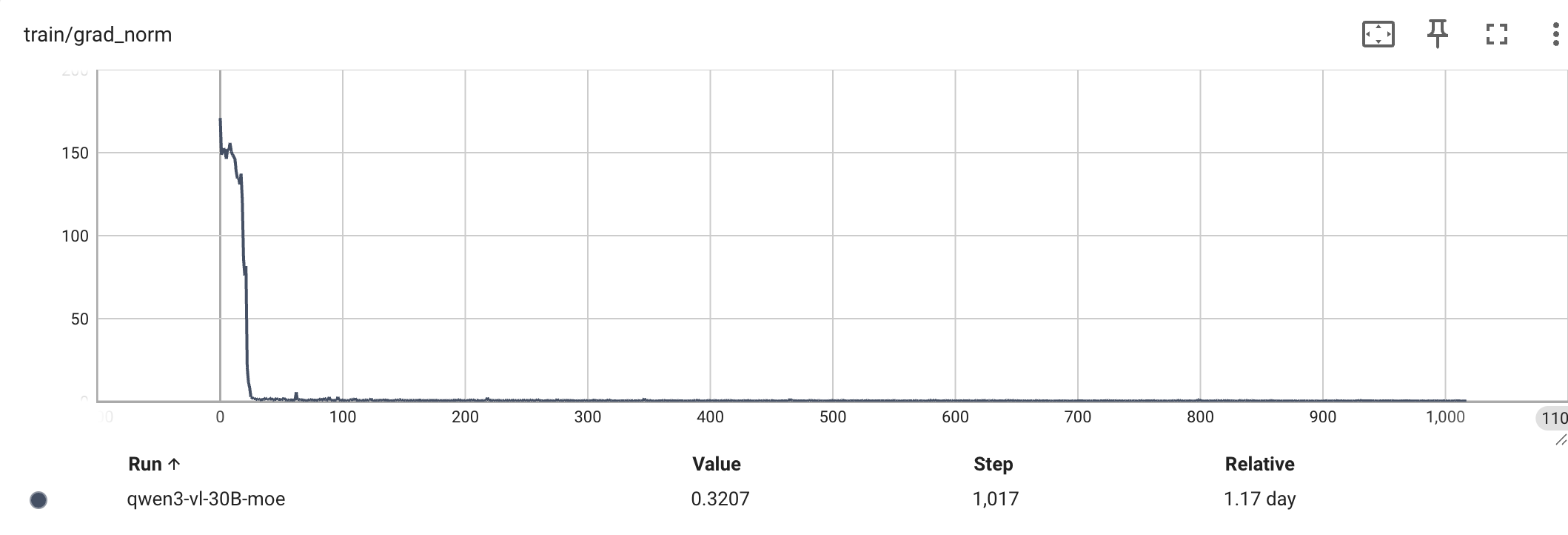
Qwen3-VL-30B-A3B(MoE) —— 1000 次迭代的 grad_norm 与 loss 曲线:
检查点转换#
使用 FSDP 训练时,SFT 保存的是 FSDP 格式权重(如 full_weights.pt)。若需要 HuggingFace
格式,请使用内置转换脚本 rlinf/utils/ckpt_convertor/fsdp_convertor/convert_pt_to_hf.py
和 fsdp_model_convertor 配置。先在
rlinf/utils/ckpt_convertor/fsdp_convertor/config/fsdp_model_convertor.yaml 中设置以下字段:
convertor.ckpt_path:指向full_weights.ptconvertor.save_path:输出 HF 权重目录model.model_path:原始基座模型路径model.model_type:对应模型类型(如qwen2.5_vl、qwen3_vl或qwen3_vl_moe)
然后运行:
python -m rlinf.utils.ckpt_convertor.fsdp_convertor.convert_pt_to_hf \
--config-path rlinf/utils/ckpt_convertor/fsdp_convertor/config \
--config-name fsdp_model_convertor
详见 检查点转换。
字段说明#
micro_batch_size:单卡一次前向/反向的样本数。global_batch_size:全局 batch(需满足可整除关系)。max_epochs:按数据集完整遍历的轮数。save_interval:每多少 step 保存一次 checkpoint。model_path:本地模型目录(必须存在)。train_data_paths/val_data_paths:数据目录或文件路径。
常见报错与排查#
找不到模型路径 —— 检查
actor.model.model_path是否正确、是否有读取权限。数据字段不匹配 —— 检查
prompt_key/choice_key/answer_key/image_keys是否与数据实际列名一致。显存不足(OOM) —— 先降低
micro_batch_size,再减少num_workers;仍不足时缩小模型或降低输入长度。只想先跑通流程 —— 使用很小的数据子集,将
max_epochs设为 1,并把save_interval设小一些以便观察。