Franka 真机强化学习#

基础 RLinf 真机 RL 流程使用的 Franka Emika Panda 机械臂。#
使用 RLinf 在 Franka Emika Panda 机械臂上训练和评测真机策略。你将配置控制节点与训练节点,采集示教数据,运行 SAC / RLPD 或 PPO 类训练,并在真实硬件上监控安全的在线更新。
相关 Franka 配置#
探索其他 Franka 硬件、传感器与训练配方。
使用学习到的奖励模型训练 Franka。
使用 ZED 相机与 Robotiq 夹爪。
使用 GELLO 进行关节级遥操作数据采集。
使用 VR / PICO 设备进行遥操作。
为 Franka 配置灵巧手末端执行器。
在 Franka 上部署 π₀ SFT 策略。
人类介入的 DAgger 交互式训练。
运行双臂 Franka 配置。
使用 PICO 采集双臂数据并运行 HG-DAgger。
概览#
从相机观测和机器人反馈中训练真机操作策略。
CNN policy · OpenPI π₀.₅
SAC · Cross-Q · RLPD · PPO
Peg insertion · charger · PnP
Franka · RealSense/ZED · gripper
env/reward 和视频.任务#
任务 |
配置 / 入口 |
说明 |
|---|---|---|
Peg insertion |
|
在目标末端位姿完成插块插入。 |
Charger |
|
通过真机奖励反馈完成充电器对齐与插入。 |
PnP / eval |
|
采集或部署 pick-and-place 类策略。 |
观测与动作#
字段 |
说明 |
|---|---|
Observation |
RGB 相机帧,以及可选机器人状态。 |
Action |
6D/7D 连续笛卡尔增量动作,可包含夹爪控制。 |
Reward |
任务成功、键盘标注或任务特定稠密反馈。 |
Prompt |
使用 VLA 策略时由 env config 提供真机任务文本。 |
硬件环境搭建#
真实世界实验需要如下硬件组件:
机械臂:Franka Emika Panda 机械臂。
相机:Intel RealSense 相机(默认)或 Stereolabs ZED 相机。
夹爪:Franka 夹爪(默认)或 Robotiq 2F-85/2F-140。
计算节点:一台带有 GPU 的计算机,用于训练 CNN 策略。
机器人控制节点:一台与机械臂处于同一局域网的小型计算机(不需要 GPU),用于控制 Franka 机械臂。
空间鼠标(可选):用于远程操控数据采集或在训练过程中进行人工干预。
GELLO(可选):一种关节级遥操作设备,可替代空间鼠标,操控更直观,并原生支持夹爪控制。
VR / PICO(可选):通过 PICO 头显和手柄进行 6D 末端遥操作,可替代空间鼠标进行数据采集。
警告
请确保所有计算机均处于同一局域网络中。 机械臂本体只需要与机器人控制节点处于同一局域网即可。
备注
使用 ZED 相机或 Robotiq 夹爪? 请参考专门的指南 在 Franka 上使用 ZED + Robotiq,了解 SDK 安装、串口设备配置、 YAML 配置字段以及数据采集。
使用 VR / PICO 遥操作? 请参考 Franka 真机使用 VR 遥操作设备,了解 XRoboToolkit、ZeroMQ、PICO wrapper 配置以及操作步骤。
安装#
控制节点与训练 / rollout 节点需要安装不同的软件依赖。
机器人控制节点#
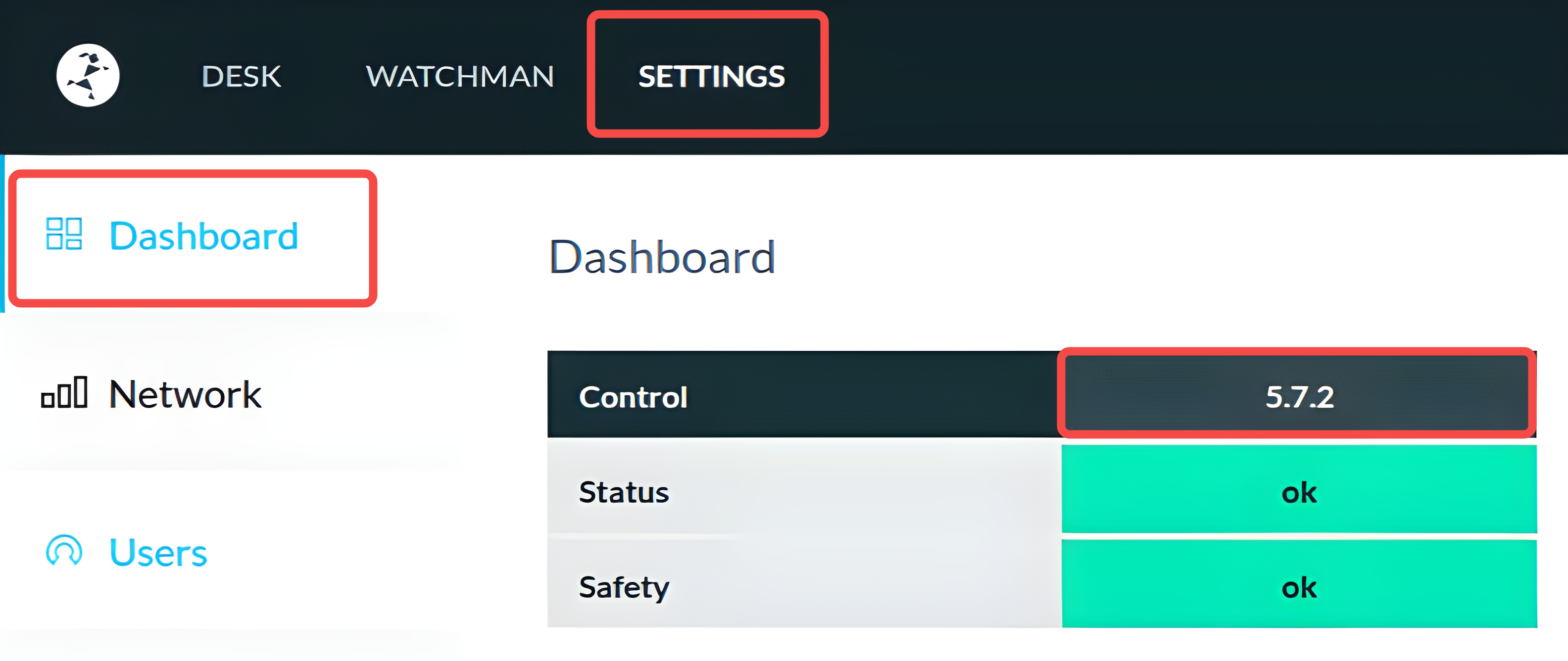
1. 检查 Franka 固件版本#
在机器人管理网页(一般为 http://<robot_ip>/desk)中,点击 SETTINGS 选项卡,在 DashBoard 中查看 Control 后面的版本号,如下所示。
请记录该固件版本号,后续步骤会用到。
警告
请确保 Franka 固件版本 <5.9.0 以保证与 serl_franka_controllers 的兼容性。
推荐使用固件版本 5.7.2 以获得最佳兼容性。
2. 实时内核安装#
推荐在实时内核(Real-time Kernel)上运行 Franka 控制程序,以获得更好的实时性。 请参考 Franka 官方文档 安装实时内核。
3. 依赖安装#
A. 克隆 RLinf 仓库#
# 为了提高国内下载速度,也可以使用:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
B. 安装依赖#
方式 1:Docker 镜像
使用 Docker 镜像进行实验。
为了从 Docker 容器内访问机器人、相机和空间鼠标设备,建议使用以下附加参数运行容器:
docker run -it --rm \
--privileged \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-franka
# 为了提高国内下载速度,也可以使用:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-franka
目前该 Docker 镜像包含 libfranka 版本 0.10.0、0.13.3、0.14.1、0.15.0 和 0.18.0,以及 franka_ros 版本 0.10.0。
这些版本均基于 Franka 兼容性矩阵 进行选择。 请检查你的 Franka 固件版本,并找到与之兼容的 libfranka 版本。
确定兼容的 libfranka 版本后,可以通过运行以下命令在 docker 容器中切换到对应的虚拟环境:
source switch_env franka-<libfranka_version>
# 例如,对于 libfranka 版本 0.15.0
# source switch_env franka-0.15.0
方式 2:自定义环境
安装脚本主要包含两部分内容:
RLinf 框架及真实世界强化学习训练所需的 Python 依赖;
用于 Franka 控制的 ROS Noetic、libfranka、franka_ros 以及 serl_franka_controllers 等依赖。
警告
由于 ROS Noetic 的要求,安装脚本目前 仅支持 Ubuntu 20.04。
警告
如果你已经手动安装了 ROS Noetic、libfranka、franka_ros 和 serl_franka_controllers,
可以在运行安装脚本前设置环境变量 export SKIP_ROS=1 来跳过这些组件的安装。
如果你跳过了这些安装,请务必保证已经在 ~/.bashrc 中 source 了 ROS 的 setup 脚本(通常位于 /opt/ros/noetic/setup.bash),
以及 franka_ros 和 serl_franka_controllers 的 setup 脚本(通常位于 <your_catkin_ws>/devel/setup.bash),
同时确保 libfranka 的动态库已经加入 LD_LIBRARY_PATH,或者安装在系统库目录 /usr/lib 中。
在每次启动控制节点上的 ray 之前,都需要确保这些环境变量和依赖已经正确加载, 否则可能会导致 Franka 控制相关包无法被正确找到。
警告
目前,ROS Noetic、libfranka 和 franka_ros 的自动安装仅在固件版本 >=5.7.2 且 <5.9.0 的 Franka 上进行过测试,
该范围内推荐使用 libfranka 版本 0.15 和 franka_ros 版本 0.10。
对于其他固件版本,请先参考 Franka 兼容性矩阵,
然后通过设置环境变量 export LIBFRANKA_VERSION=<version> 与 export FRANKA_ROS_VERSION=<version> 自行指定 libfranka 和 franka_ros 的版本,再运行安装脚本。
备注
如果安装脚本对你不适用,可参考官方文档 ROS Noectic 安装说明 , Franka 安装说明 ,和 serl_franka_controllers 安装说明 进行手动安装。
执行以下命令安装控制节点依赖:
# 为提高国内依赖安装速度,可以添加`--use-mirror`到下面的install.sh命令
bash requirements/install.sh embodied --env franka
source .venv/bin/activate
训练 / Rollout 节点#
A. 克隆 RLinf 仓库#
# 为了提高国内下载速度,也可以使用:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
B. 安装依赖#
方式 1:Docker 镜像
使用 Docker 镜像进行实验。
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# 为了提高国内下载速度,也可以使用:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
方式 2:自定义环境(Custom Environment)
在本地环境中直接安装依赖:
# 为提高国内依赖安装速度,可以添加`--use-mirror`到下面的install.sh命令
bash requirements/install.sh embodied --model openvla --env maniskill_libero
source .venv/bin/activate
下载模型#
在开始训练之前,需要先下载对应的预训练模型:
# 下载模型(两种方式二选一)
# 方式 1:使用 git clone
git lfs install
git clone https://huggingface.co/RLinf/RLinf-ResNet10-pretrained
git clone https://huggingface.co/RLinf/RLinf-ResNet10-pretrained
# 方式 2:使用 huggingface-hub
# 为了提高国内下载速度,可以添加以下环境变量:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-ResNet10-pretrained --local-dir RLinf-ResNet10-pretrained
hf download RLinf/RLinf-ResNet10-pretrained --local-dir RLinf-ResNet10-pretrained
下载完成后,请在对应的配置 YAML 文件中正确填写模型路径。
运行#
前置准备#
获取任务的目标位姿
对于 Peg-insertion 任务,可以使用脚本 toolkits.realworld_check.test_franka_controller 获取目标末端位姿。
首先,需要将 Franka 机器人切换到可编程模式,然后手动将机械臂移动到希望的目标位姿。
随后,在运行脚本之前,先设置环境变量 FRANKA_ROBOT_IP 为机器人 IP 地址:
export FRANKA_ROBOT_IP=<your_robot_ip_address>
然后运行脚本:
python -m toolkits.realworld_check.test_franka_controller
脚本会提示你输入命令,可以输入 getpos_euler 来获取当前末端执行器以欧拉角形式表示的位姿。
数据采集#
对于 RLPD 实验,需要先在控制节点上收集一部分初始数据, 该过程只需在控制节点上运行,不需要其他节点参与。
依次激活虚拟环境并 source franka_ros 与 serl_franka_controllers 的 setup 脚本:
source <path_to_your_venv>/bin/activate
source <your_catkin_ws>/devel/setup.bash
修改配置文件
examples/embodiment/config/realworld_collect_data.yaml, 将其中robot_ip字段填为你的机器人 IP 地址。
cluster:
num_nodes: 1
component_placement:
env:
node_group: franka
placement: 0
node_groups:
- label: franka
node_ranks: 0
hardware:
type: Franka
configs:
- robot_ip: ROBOT_IP
node_rank: 0
将配置中的 target_ee_pose 字段改为前面步骤中获取到的目标末端位姿:
env:
eval:
override_cfg:
target_ee_pose: [0.5, 0.0, 0.1, -3.14, 0.0, 0.0]
运行数据采集脚本:
bash examples/embodiment/collect_data.sh
在采集过程中,可以使用空间鼠标对机器人进行人工干预,以获得更丰富的数据。
脚本默认在收集 20 个 episode 后结束(可以通过配置中的 num_data_episodes 字段修改),
采集到的数据会保存在 logs/[running-timestamp]/data.pkl 路径下。
数据采集完成后,可以将收集到的数据上传到训练 / rollout 节点。
备注
使用 ZED 相机和 Robotiq 夹爪? 我们提供了专用的数据采集脚本和配置文件。 请参考 在 Franka 上使用 ZED + Robotiq 中的 数据采集 章节。
使用 GELLO 进行数据采集#
除空间鼠标外,RLinf 还支持使用 GELLO 进行遥操作数据采集。 GELLO 是一种关节级遥操作设备,其运动学结构与 Franka 机械臂一致,操控更直观、精确,并原生支持夹爪控制。
前置条件
安装
gello和gello-teleop软件包。详细安装说明请参考 在 Franka 上使用 GELLO。GELLO 设备通过 USB 串口连接到控制节点。
确认 GELLO 串口路径(例如
/dev/serial/by-id/usb-FTDI_USB__-__Serial_Converter_FTA0OUKN-if00-port0)。 可通过以下命令列出可用串口:ls /dev/serial/by-id/
配置
使用配置文件 examples/embodiment/config/realworld_collect_data_gello.yaml。
与空间鼠标配置的关键区别如下:
env:
eval:
use_spacemouse: False
use_gello: True
gello_port: "/dev/serial/by-id/usb-FTDI_..." # 替换为你的 GELLO 串口路径
运行
bash examples/embodiment/collect_data.sh realworld_collect_data_gello
整体流程与空间鼠标采集相同:使用 GELLO 设备操控机器人完成任务,脚本会自动保存成功的 episode。
集群设置#
在正式开始实验之前,需要先正确地搭建 ray 集群。
警告
这一步非常关键,请谨慎操作!任何细微的配置错误,都可能导致依赖缺失或无法正确控制机器人。
RLinf 使用 ray 来管理分布式环境,这意味着:
当你在某个节点上执行 ray start 时,ray 会记录当时的 Python 解释器路径和相关环境变量;
之后在该节点上由 ray 启动的所有进程都会继承同一套 Python 环境与环境变量。
我们提供了脚本 ray_utils/realworld/setup_before_ray.sh,
用于在每个节点启动 ray 之前帮助你统一设置环境。你可以根据自己的环境修改该脚本,并在每个节点上 source 它。
该脚本主要负责以下内容:
在使用自定义环境安装方式时,source 正确的虚拟环境,请参考依赖安装部分的说明;
在控制节点上,source franka_ros 与 serl_franka_controllers 的 setup 脚本(通常位于
<your_catkin_ws>/devel/setup.bash),如果你使用的是 docker 镜像或安装脚本,则在 source 虚拟 Python 环境时已经完成此操作;在所有节点上设置 RLinf 相关环境变量:
export PYTHONPATH=<path_to_your_RLinf_repo>:$PYTHONPATH
export RLINF_NODE_RANK=<node_rank_of_this_node>
export RLINF_COMM_NET_DEVICES=<network_device_for_communication> # 如果只有一个网卡可以省略
其中 RLINF_NODE_RANK 应在集群的 N 个节点之间设置为 0 ~ N-1,
用来在配置文件中唯一标识每个节点。
RLINF_COMM_NET_DEVICES 为可选项,仅在机器拥有多个网络设备(例如 eth0、enp3s0 等)时需要设置,
应当指定提供其他节点可访问 IP 的那块网卡。可以通过 ifconfig 或 ip addr 查看。
在完成上述环境设置后,可以按如下方式在各节点上启动 ray:
其中 <head_node_ip_address> 为 head 节点的 IP 地址,必须 能被集群中其他节点访问。
# 在 head 节点(节点 rank 0)上
ray start --head --port=6379 --node-ip-address=<head_node_ip_address>
# 在 worker 节点(节点 rank 1 ~ N-1)上
ray start --address='<head_node_ip_address>:6379'
可以通过执行 ray status 来检查集群是否已正确启动。
配置文件#
正式运行实验前,需要根据实际集群与机器人设置修改配置文件
examples/embodiment/config/realworld_peginsertion_rlpd_cnn_async.yaml。
首先,在配置文件中将 robot_ip 字段设置为机器人 IP 地址,将 target_ee_pose 字段设置为目标末端位姿。
接着,在 rollout 与 actor 部分,将 model_path 字段修改为前面下载好的预训练模型路径;
同时,将 data.path 字段设置为你上传 demo 数据的位置。
无显示器键盘奖励包装器(可选)#
如果你希望通过人工使用物理键盘给奖励打标,可以在 real-world env 配置中启用键盘包装器。
例如,在 examples/embodiment/config/realworld_peginsertion_rlpd_cnn_async.yaml 中加入:
env:
train:
keyboard_reward_wrapper: single_stage # 或 multi_stage
可用模式如下:
single_stage:按a记失败奖励,按b记中性奖励,按c记成功奖励。multi_stage:按a/b/c在不同奖励阶段之间切换,按q输出负奖励。
新的键盘监听器会直接读取 Linux 输入设备,因此需要在控制节点上、执行 ray start 之前导出 RLINF_KEYBOARD_DEVICE。
首先,查看当前机器上的键盘设备:
ls -l /dev/input/by-id/*-event-kbd
该命令会显示稳定的键盘名称以及其对应的 eventX 设备。例如,usb-Logitech_USB_Keyboard-event-kbd -> ../event20 表示对应的键盘设备是 /dev/input/event20。
开始训练前,先给该 event 设备开放访问权限:
chmod 666 /dev/input/event20
然后在启动 ray 之前,于 shell 或 setup 脚本中导出这个 event 设备:
export RLINF_KEYBOARD_DEVICE=/dev/input/event20
如果你使用的是 ray_utils/realworld/setup_before_ray.sh,建议在控制节点的该脚本中加入这条 export,确保 ray 启动的 env 进程能够继承这个环境变量。
检查环境(可选)#
在启动正式实验前,我们推荐先通过若干测试脚本验证整体环境配置是否正确。
首先,在控制节点上测试相机连接:
python -m toolkits.realworld_check.test_franka_camera
然后,通过运行一个 dummy 版本配置来测试基础集群配置。请参照``examples/embodiment/config/realworld_dummy_franka_sac_cnn.yaml``文件添加`env.eval.override_cfg`。
可以在配置文件中同时将 env.train.override_cfg 与 env.eval.override_cfg 部分的 is_dummy 字段设置为 True,
以启用 dummy 模式。请注意如果启用dummy模式,需要将上面运行 toolkits.realworld_check.test_franka_camera.py 得到的camera序列号
填补在 env.train.override_cfg 与 env.eval.override_cfg 部分的 camera_serials 字段。
在 head 节点上运行测试脚本:
bash examples/embodiment/run_realworld_async.sh realworld_peginsertion_rlpd_cnn_async
运行#
在完成上述检查之后,即可在 head 节点上启动真实世界训练实验:
bash examples/embodiment/run_realworld_async.sh realworld_peginsertion_rlpd_cnn_async
进阶:多机器人配置#
RLinf 支持对多台 Franka 机器人进行统一管理,实现并行数据采集与训练。
要启用多机器人设置,需要在配置文件的 node_groups 部分为每个机器人添加独立的配置。
一个包含两台 Franka 机器人的配置示例位于
examples/embodiment/config/realworld_peginsertion_rlpd_cnn_async_2arms.yaml,如下所示:
cluster:
num_nodes: 3 # 1 个训练 / rollout 节点 + 2 个机器人控制节点
component_placement:
actor:
node_group: "4090"
placement: 0 # 运行在训练 / rollout 节点的第一个 GPU 上
env:
node_group: franka
placement: 0-1 # 两个 env 分别绑定两个机器人,rank 0 和 rank 1
rollout:
node_group: "4090"
placement: 0:0-1 # 在训练 / rollout 节点第一个 GPU 上运行两个 rollout 进程
node_groups:
- label: "4090"
node_ranks: 0 # 节点 rank 0 为训练 / rollout 节点
- label: franka
node_ranks: 1-2 # 节点 rank 1 和 2 为两个机器人控制节点
hardware:
type: Franka
configs:
- robot_ip: ROBOT_IP_FOR_RANK1
node_rank: 1 # 第一个机器人控制节点的 rank
- robot_ip: ROBOT_IP_FOR_RANK2
node_rank: 2 # 第二个机器人控制节点的 rank
自然地,你可以按照同样的方式扩展到更多的机器人。 关于此类异构硬件配置语法的更多细节,请参考 异构硬件配置。
可视化与结果#
1. TensorBoard 日志
# 启动 TensorBoard
tensorboard --logdir ./logs --port 6006
2. 关键监控指标
环境指标:
env/episode_len:该回合实际经历的环境步数(单位:step)env/return:回合总回报env/reward:环境的 step-level 奖励env/success_once:回合中至少成功一次标志(0或1)
Training Metrics:
train/sac/critic_loss: Q 函数的损失train/critic/grad_norm: Q 函数的梯度范数train/sac/actor_loss: 策略损失train/actor/entropy: 策略熵train/actor/grad_norm: 策略的梯度范数train/sac/alpha_loss: 温度参数的损失train/sac/alpha: 温度参数的值train/alpha/grad_norm: 温度参数的梯度范数train/replay_buffer/size: 当前重放缓冲区的大小train/replay_buffer/max_reward: 重放缓冲区中存储的最大奖励train/replay_buffer/min_reward: 重放缓冲区中存储的最小奖励train/replay_buffer/mean_reward: 重放缓冲区中存储的平均奖励train/replay_buffer/std_reward: 重放缓冲区中存储的奖励标准差train/replay_buffer/utilization: 重放缓冲区的利用率
真实世界结果#
以下提供了插块插入任务和充电器任务的演示视频和训练曲线。在 1 小时的训练时间内,机器人能够学习到一套能够持续成功完成任务的策略。
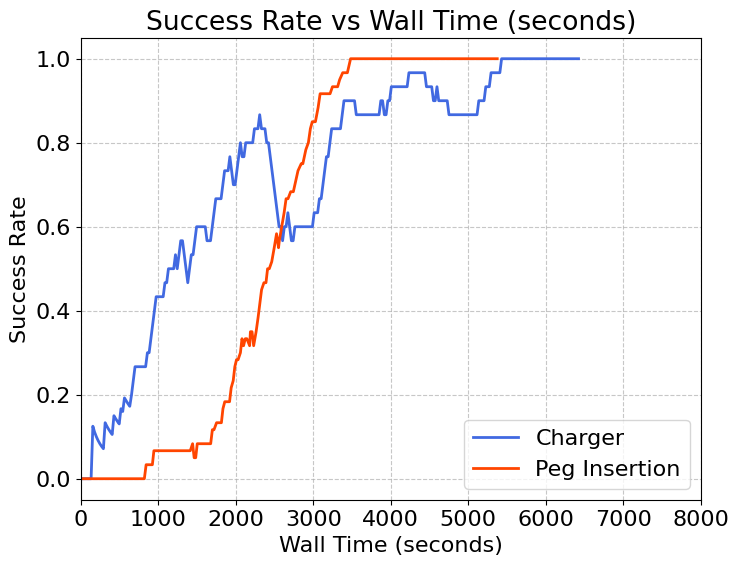
训练曲线
插块插入(Peg Insertion)
充电器插电(Charger)