DSRL:基于扩散模型的潜在空间强化学习#
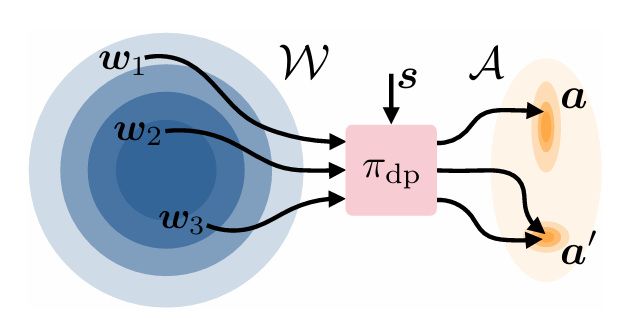
DSRL 在噪声空间中操控冻结的扩散策略。#
使用 DSRL(Diffusion Steering via Reinforcement Learning) 对预训练的 Pi0 扩散策略 做强化学习微调。DSRL 在潜在噪声空间中训练轻量 SAC 智能体来引导冻结的 Pi0 策略,仅需约 500K 可训练参数。
相关论文: Steering Your Diffusion Policy with Latent Space Reinforcement Learning (CoRL 2025, Wagenmaker et al.)
参考实现: dsrl_pi0
核心思路:
轻量级 SAC 智能体:一个小型 SAC 智能体(约 500K 参数),配备紧凑的 CNN/MLP 编码器,处理观测并在潜在空间中生成噪声。
噪声注入:生成的噪声作为初始噪声输入到 Pi0 的扩散去噪器中,替代随机采样。
冻结 VLM 主干:预训练的 Pi0 VLM 和扩散专家模块保持冻结,保留泛化能力。
噪声空间中的 SAC 训练:SAC 智能体在噪声空间上使用环境奖励进行训练,采用 10 个 Q-head 集成的 Critic 实现稳定的价值估计。
概览#
用一个轻量 SAC 智能体(约 50 万参数)在潜在噪声空间中操控冻结的 π₀ 扩散策略。
DSRL (SAC)
π₀(冻结)
LIBERO-Spatial
~500K 可训练参数
run_embodiment.sh → 观察 env/success_once。任务#
字段 |
说明 |
|---|---|
环境 |
LIBERO-Spatial——强调空间推理的桌面操作。 |
观测 |
8 维本体感知 + RGB 图像。 |
动作 |
由 π₀ 冻结的扩散去噪器生成的连续动作,由 SAC 噪声操控。 |
DSRL 工作原理#
DSRL 流程
观测编码:轻量级 CNN(64×64 → 64维)和状态编码器(8维 → 64维)处理观测数据。
噪声生成:
GaussianPolicy(SquashedNormal 分布)为每个动作步生成 32 维噪声动作。扩散去噪:噪声作为初始噪声注入 Pi0 的
sample_actions(),冻结的扩散去噪器将噪声转换为真实动作。SAC 训练:标准 SAC 配合自动熵调节训练噪声生成器:
Actor:
GaussianPolicy,3 层 MLP(128维隐藏层)Critic:
CompactMultiQHead— 10 个 Q 网络集成(共约 500K 参数)目标网络:Float32 EMA 影子缓冲区,解决 bfloat16 精度问题
安装#
DSRL 使用与 Pi0 相同的环境和模型依赖。请参考 π0和π0.5模型强化学习训练 获取完整的安装指南,包括 Docker 镜像配置、依赖安装和模型下载。
运行#
1. 配置文件
DSRL 训练:
examples/embodiment/config/libero_spatial_dsrl_openpi.yaml
2. 关键参数配置
2.1 DSRL 模型参数
actor:
model:
openpi:
use_dsrl: True # 启用 DSRL 模式
dsrl_state_dim: 8 # 机器人本体感知维度
dsrl_action_noise_dim: 32 # 每步噪声动作维度
dsrl_num_q_heads: 10 # 集成 Critic 中的 Q-head 数量
dsrl_image_latent_dim: 64 # 图像编码器输出维度
dsrl_state_latent_dim: 64 # 状态编码器输出维度
dsrl_hidden_dims: [128, 128, 128] # MLP 隐藏层维度
2.2 算法参数
algorithm:
adv_type: embodied_sac
loss_type: embodied_sac
gamma: 0.999 # 折扣因子
tau: 0.005 # 目标网络软更新系数
update_epoch: 200 # 每次交互后的训练步数
train_actor_steps: 10 # Actor 训练延迟步数(先训练 Critic)
entropy_tuning:
alpha_type: softplus
initial_alpha: 1.0
target_entropy: -16
optim:
lr: 3.0e-4
2.3 环境参数
env:
train:
total_num_envs: 16
use_step_penalty: True # 使用 -1/0 奖励风格(步惩罚 + 终止奖励)
max_episode_steps: 240
eval:
total_num_envs: 500
use_step_penalty: True
3. 启动命令
bash examples/embodiment/run_embodiment.sh libero_spatial_dsrl_openpi
可视化与结果#
1. TensorBoard 日志
# 启动 TensorBoard
tensorboard --logdir ./logs
2. 关键监控指标
指标含义见 训练指标。DSRL 相关指标:
环境指标:
env/episode_len:该回合实际经历的环境步数env/return:回合总回报env/reward:环境的 step-level 奖励env/success_once:回合中至少成功一次标志(0 或 1)
训练指标:
train/sac/critic_loss:Q 函数集成的损失train/critic/grad_norm:Q 函数的梯度范数train/sac/actor_loss:策略损失(噪声空间中的 GaussianPolicy)train/actor/entropy:策略熵train/actor/grad_norm:策略的梯度范数train/sac/alpha_loss:温度参数的损失train/sac/alpha:温度参数的值train/replay_buffer/size:当前重放缓冲区的大小train/replay_buffer/utilization:重放缓冲区的利用率