MLP策略强化学习训练#
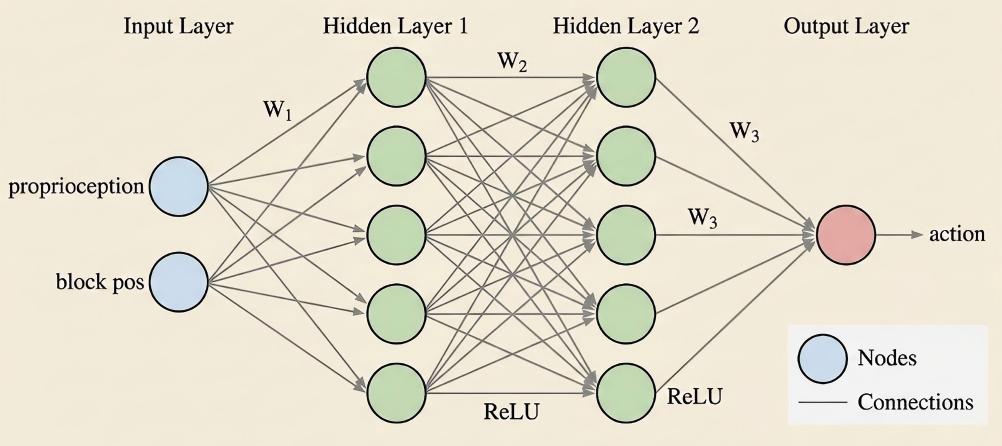
多层感知机(MLP)策略。#
MLP 策略是一种轻量网络,用于从低维状态输入(关节角、末端执行器位姿、物体状态等)进行机器人控制。 RLinf 在多个仿真器上用 PPO、SAC、GRPO 训练 MLP 策略——便于快速验证环境、训练流程与网络结构。
概览#
在低维状态下,用 PPO/SAC/GRPO 在 ManiSkill、LIBERO-Spatial、FrankaSim 上训练 MLP 策略。
ManiSkill · LIBERO · FrankaSim
PPO · SAC · GRPO
PickCube · LIBERO-Spatial
1 节点 · GPU
run_embodiment.sh → 观察 env/success_once。任务#
通过 defaults 列表选择环境(env/<env_name>@env.train / @env.eval);可在 env.train / env.eval 下覆写并行环境数、回合长度与录制等参数。
环境 |
任务 / 套件 |
配置 / 权重 |
重点 |
|---|---|---|---|
ManiSkill3 |
PickCube |
|
基于低维状态的策略训练。 |
LIBERO |
LIBERO-Spatial |
|
在 LIBERO spatial 任务上使用 MLP 策略运行 GRPO。 |
MuJoCo / FrankaSim |
PickCube |
|
FrankaSim 中基于状态的 PPO 训练。 |
观测与动作#
字段 |
说明 |
|---|---|
Observation |
低维状态向量,例如机器人关节、末端执行器位姿和物体状态。 |
Action |
由 |
Reward |
仿真器任务奖励或成功信号。 |
Prompt |
MLP 策略不使用 prompt;任务通过 Hydra 配置选择。 |
安装#
对于在仿真环境运行,请参考 安装说明 进行安装。
本系列配置使用 Hydra 的 searchpath 从环境变量引入外部配置目录:
hydra.searchpath: file://${oc.env:EMBODIED_PATH}/config/
请确保已正确设置 EMBODIED_PATH,并安装 ManiSkill3 / FrankaSim 相关依赖与资源。
运行#
1. 配置文件
RLinf 提供多份 MLP 默认配置,覆盖不同环境与算法设置:
ManiSkill + PPO + MLP:
maniskill_ppo_mlpManiSkill + SAC + MLP:
maniskill_sac_mlpFrankaSim + PPO + MLP:
frankasim_ppo_mlp
2. 关键参数配置
2.1 模型参数 (Model)
MLP 模型由 model/mlp_policy@actor.model 引入,并在不同配置中做覆盖。常见关键字段如下:
model_type: "mlp_policy" # 使用 MLP 策略网络作为 actor(多层感知机;适合低维 state 输入)
model_path: ""
policy_setup: "panda-qpos" # 选择动作语义与控制模式;panda-qpos 通常表示关节空间控制(如 qpos/关节目标或增量)
obs_dim: 42 # 输入到 MLP 的状态向量维度(需与环境输出的 state 维度严格一致)
action_dim: 8 # 策略输出动作向量的维度(需与环境 action space 维度严格一致)
num_action_chunks: 1 # 一次 forward 生成的动作 chunk
hidden_dim: 256 # MLP 隐藏层的通道/宽度
precision: "32" # 模型参数与计算精度;
add_value_head: True # 是否在策略网络上额外挂载 value head
is_lora: False # 是否启用 LoRA(
lora_rank: 32 # LoRA 的低秩维度 r;仅当 is_lora=True 时生效
- 2.2 集群与硬件配置 (Cluster)
对于真机训练,使用多节点配置,将 Actor/Policy 部署在 GPU 服务器上,将 Env/Robot 部署在控制机(NUC/工控机)上。具体配置可参考 Franka 真机强化学习 。
3. 启动命令
ManiSkill(PPO-MLP)
bash examples/embodiment/run_embodiment.sh maniskill_ppo_mlp
ManiSkill(SAC-MLP)
bash examples/embodiment/run_embodiment.sh maniskill_sac_mlp
备注
SAC 注意事项。 SAC 通过 Bellman 回传与熵正则学习 Q 值(off-policy),因此需在配置中启用
Q 相关的 head(add_q_head: True)。它还支持通过 entropy_tuning 进行自动熵调节
(如 alpha_type: softplus),以平衡探索与利用。
Libero-Spatial(GRPO-MLP)
bash examples/embodiment/run_embodiment.sh libero_spatial_0_grpo_mlp
FrankaSim(PPO-MLP)
bash examples/embodiment/run_embodiment.sh frankasim_ppo_mlp
可视化与结果#
1. TensorBoard 日志
# 启动 TensorBoard
tensorboard --logdir ../results
2. 关键指标
最值得关注的指标是 ``env/success_once`` —— 任务成功率。每个日志指标的含义见 训练指标。