基于 Franka-Sim 的强化学习训练#

RLinf SERL fork 中的 Franka-Sim 资源。#
Franka-Sim 是基于 SERL 栈构建的轻量级 Franka Panda 仿真环境。你将使用 RLinf 在状态观测上用 PPO 训练 MLP policy,或在 RGB 观测上用异步 SAC 训练 CNN policy。
概览#
使用状态观测或视觉观测训练 Franka pick-cube 策略。
MLP · CNN
PPO · SAC
PickCube state · vision
1 节点 · 1 GPU
env/success_once。任务#
任务 |
描述 |
|---|---|
|
面向 MLP + PPO 配方的状态观测 pick-cube 任务。 |
|
面向 CNN + 异步 SAC 配方的 RGB 观测 pick-cube 任务。 |
观测与动作#
字段 |
规格 |
|---|---|
观测 |
|
动作 |
4 维连续动作:3D 末端执行器位置增量和夹爪控制。 |
奖励 |
稠密任务进度奖励。 |
提示词 |
状态 MLP 配方不使用提示词;视觉策略从 env wrapper 接收任务条件观测。 |
安装#
首先,克隆 RLinf 仓库:
# 为提高国内下载速度,可以使用镜像:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
然后,使用下列两种方式之一准备依赖:预构建的 Docker 镜像(推荐)或自定义环境。
通用的安装流程(前置依赖、GPU 驱动、镜像内置的 switch_env 工具、镜像加速、常见问题排查)
在 安装说明 中统一说明;本方案中的命令仅在 Docker
镜像标签和 --env 取值上有所不同。
Docker 镜像
docker run -it --rm --gpus all \
--shm-size 32g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-frankasim
# 国内用户可使用:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-frankasim
在镜像中切换到虚拟环境:
source switch_env openvla
自定义环境
安装 Franka-Sim 依赖:
# 国内用户可添加 --use-mirror。
bash requirements/install.sh embodied --model openvla --env frankasim
source .venv/bin/activate
下载模型#
MLP + PPO 配方可跳过本节。CNN + SAC 配方需要下载 ResNet 检查点:
cd /path/to/save/model
git lfs install
git clone https://huggingface.co/RLinf/RLinf-ResNet10-pretrained
# 或使用 huggingface-hub:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-ResNet10-pretrained --local-dir RLinf-ResNet10-pretrained
然后在 examples/embodiment/config/frankasim_sac_cnn_async.yaml 中为 rollout 和 actor
设置相同的检查点路径:
rollout:
model:
model_path: /path/to/RLinf-ResNet10-pretrained
actor:
model:
model_path: /path/to/RLinf-ResNet10-pretrained
运行#
选择一个配方并启动训练:
配方 |
配置 |
入口 |
命令后缀 |
|---|---|---|---|
MLP + PPO |
|
|
|
CNN + SAC |
|
|
|
# 状态观测 PPO 配方
bash examples/embodiment/run_embodiment.sh frankasim_ppo_mlp
# 视觉 SAC 配方
bash examples/embodiment/run_async.sh frankasim_sac_cnn_async
这条命令会:
启动选定的 embodied 训练入口。
为 actor、rollout 和 Franka-Sim env 组件创建 Ray worker。
运行 rollout,计算任务奖励,并更新选定策略。
备注
两个参考配置都运行在 GPU 0。如果迁移到更大的机器,请调整
cluster.component_placement、env.train.total_num_envs 和 batch size。
可视化与结果#
在 RLinf 仓库根目录启动 TensorBoard:
tensorboard --logdir ../results --port 6006
关键指标是 env/success_once。完整指标说明见
训练指标。
如需保存 rollout 视频,请启用 video:
env:
eval:
video_cfg:
save_video: True
video_base_dir: ${runner.logger.log_path}/video/eval
配方 |
结果描述 |
|---|---|
CNN + 异步 SAC |
在原始运行使用的仿真设置中,约一小时内学习到稳定抓取策略。 |
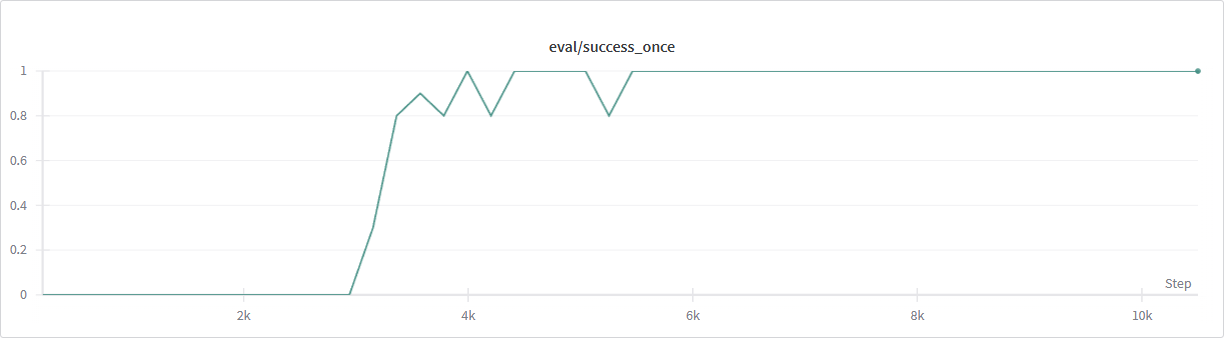
Franka-Sim 异步 SAC + CNN 成功率曲线。#