RL on StarVLA Models#
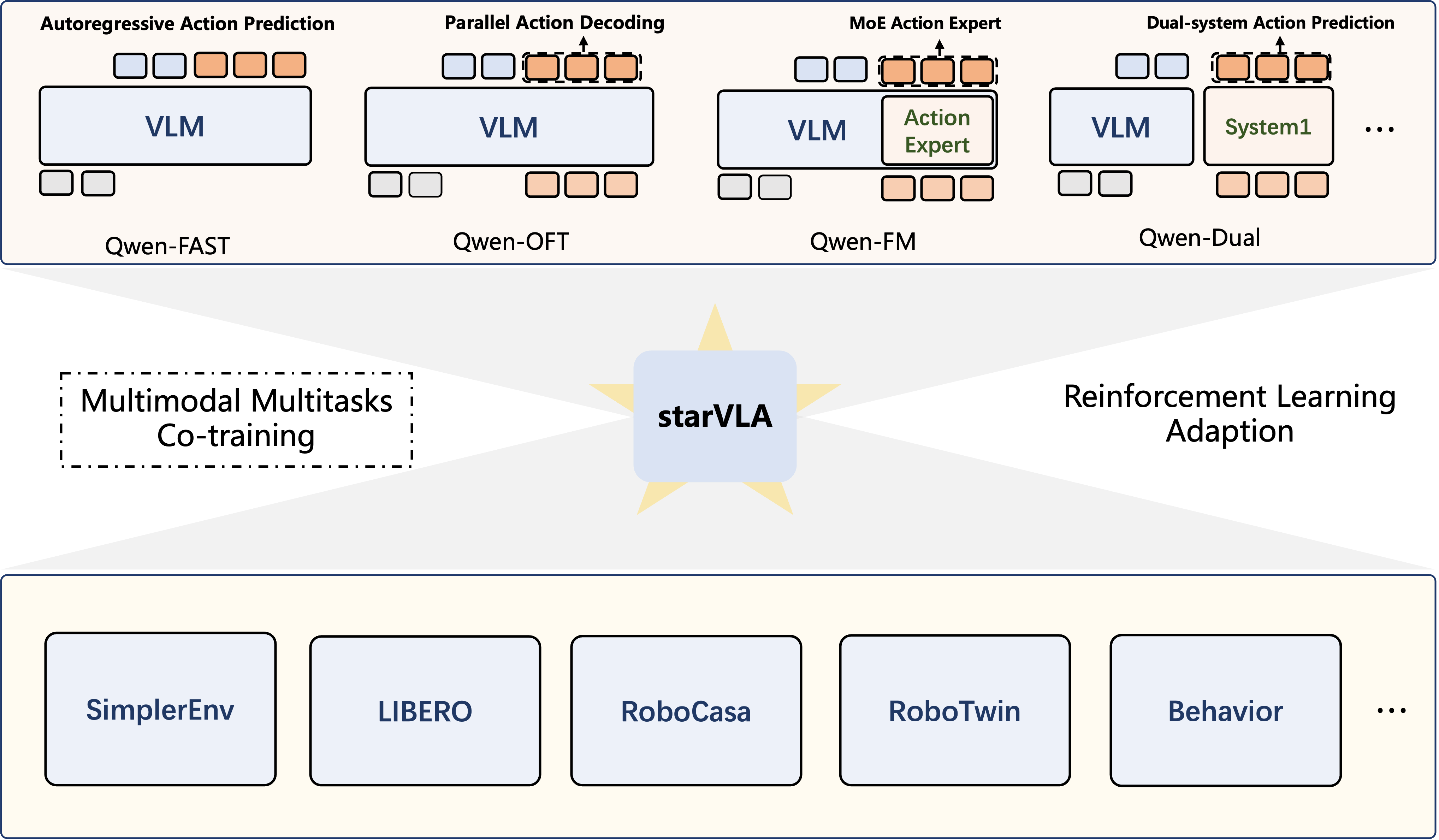
StarVLA: a modular VLM backbone + action head.#
Run RL fine-tuning for StarVLA in RLinf. StarVLA is an open-source Vision-Language-Action toolkit that composes a VLM backbone with an action head in a modular way; this example uses the QwenOFT setup and trains it on LIBERO with GRPO.
Overview#
Fine-tune StarVLA (QwenOFT) on LIBERO Spatial with GRPO.
LIBERO
GRPO
LIBERO Spatial
1 node · GPUs
run_embodiment.sh → watch env/success_once.Tasks#
Select the model page by matching the environment, task family, and config or checkpoint artifact.
Environment |
Task / Suite |
Config / Weights |
Focus |
|---|---|---|---|
LIBERO |
LIBERO-Spatial |
|
GRPO fine-tuning for StarVLA in LIBERO. |
Observation and Action#
Field |
Description |
|---|---|
Observation |
LIBERO image observations and robot state formatted for StarVLA. |
Action |
Continuous robot control commands generated through the StarVLA policy API. |
Reward |
LIBERO task success or shaped reward used by GRPO. |
Prompt |
Natural-language LIBERO task instruction. |
Interface Conventions#
In the RLinf StarVLA wrapper, env_obs is a batch-first dict (dimension 0 is batch size B).
Required fields:
main_images: main-view RGB,torch.uint8, shape[B, H, W, 3].states: proprio/state tensor,torch.float32, shape[B, D_state].task_descriptions: natural-language descriptions,list[str]with lengthB.
Optional fields:
wrist_images: wrist-view RGB,torch.uint8, shape[B, H, W, 3].extra_view_images: additional RGB views, recommended shape[B, V, H, W, 3]whereVis the number of extra views. A single extra view may also be provided as[B, H, W, 3]and is treated asV=1.
In default LIBERO usage, states is commonly end-effector position (x, y, z) (3-D),
end-effector axis-angle (rx, ry, rz) (3-D), and gripper state (originally 2-D), so
D_state is often 3 + 3 + 2 = 8. If a checkpoint expects 7-D state, the wrapper
compresses the 2-D gripper state into [x, y, z, rx, ry, rz, g_mean] where
g_mean = 0.5 * (g0 + g1).
StarVLA inference outputs chunked actions [B, T, D_action] with
T = actor.model.num_action_chunks (planning horizon) and
D_action = actor.model.action_dim (commonly 7 on LIBERO). Rollout follows a
receding-horizon strategy: each forward pass predicts T actions, the environment
executes the first N steps (1 <= N <= T), then replans.
Installation#
First, clone the RLinf repository:
# Mainland China users can use a mirror for faster cloning:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
Then set up the dependencies with one of the two methods below — a prebuilt
Docker image (recommended) or a custom environment. The general setup
(prerequisites, GPU drivers, the in-image switch_env helper, mirrors, and
troubleshooting) is documented once in Installation;
the commands in this recipe only differ in the Docker image tag and the
--env value.
Option 1: Docker image — image tag agentic-rlinf0.3-maniskill_libero:
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# Mainland China mirror: docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# Inside the container, switch to the StarVLA virtual environment:
source switch_env starvla
Option 2: Custom environment — install bundle --env maniskill_libero:
# Add --use-mirror for faster downloads in mainland China.
bash requirements/install.sh embodied --model starvla --env maniskill_libero
source .venv/bin/activate
Download the Model#
Download the StarVLA checkpoint and the base VLM:
# Method 1: git clone
git lfs install
git clone https://huggingface.co/StarVLA/Qwen2.5-VL-OFT-LIBERO-4in1
git clone https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
# Method 2: huggingface-hub (set HF_ENDPOINT=https://hf-mirror.com in mainland China)
uv pip install huggingface-hub
hf download StarVLA/Qwen2.5-VL-OFT-LIBERO-4in1 --local-dir ./Qwen2.5-VL-OFT-LIBERO-4in1
hf download Qwen/Qwen2.5-VL-3B-Instruct --local-dir ./Qwen2.5-VL-3B-Instruct
Note
After download, update Qwen2.5-VL-OFT-LIBERO-4in1/config.yaml so
framework.qwenvl.base_vlm points to your local Qwen2.5-VL-3B-Instruct path.
Run It#
1. Configuration
StarVLA + GRPO + LIBERO Spatial uses
examples/embodiment/config/libero_spatial_grpo_starvla.yaml. Point the model paths at
your download and set the action interface:
defaults:
- env/libero_spatial@env.train
- env/libero_spatial@env.eval
rollout:
model:
model_path: "/path/to/model"
actor:
model:
model_path: "/path/to/model"
action_dim: 7
num_action_chunks: 8
action_stats_source: "minmax"
starvla:
framework_name: "QwenOFT"
expected_action_dim: ${actor.model.action_dim}
expected_num_action_chunks: ${actor.model.num_action_chunks}
enable_state_input: False
2. Launch
bash examples/embodiment/run_embodiment.sh libero_spatial_grpo_starvla
For evaluation, use RLinf’s unified evaluation workflow — see the LIBERO evaluation guide.
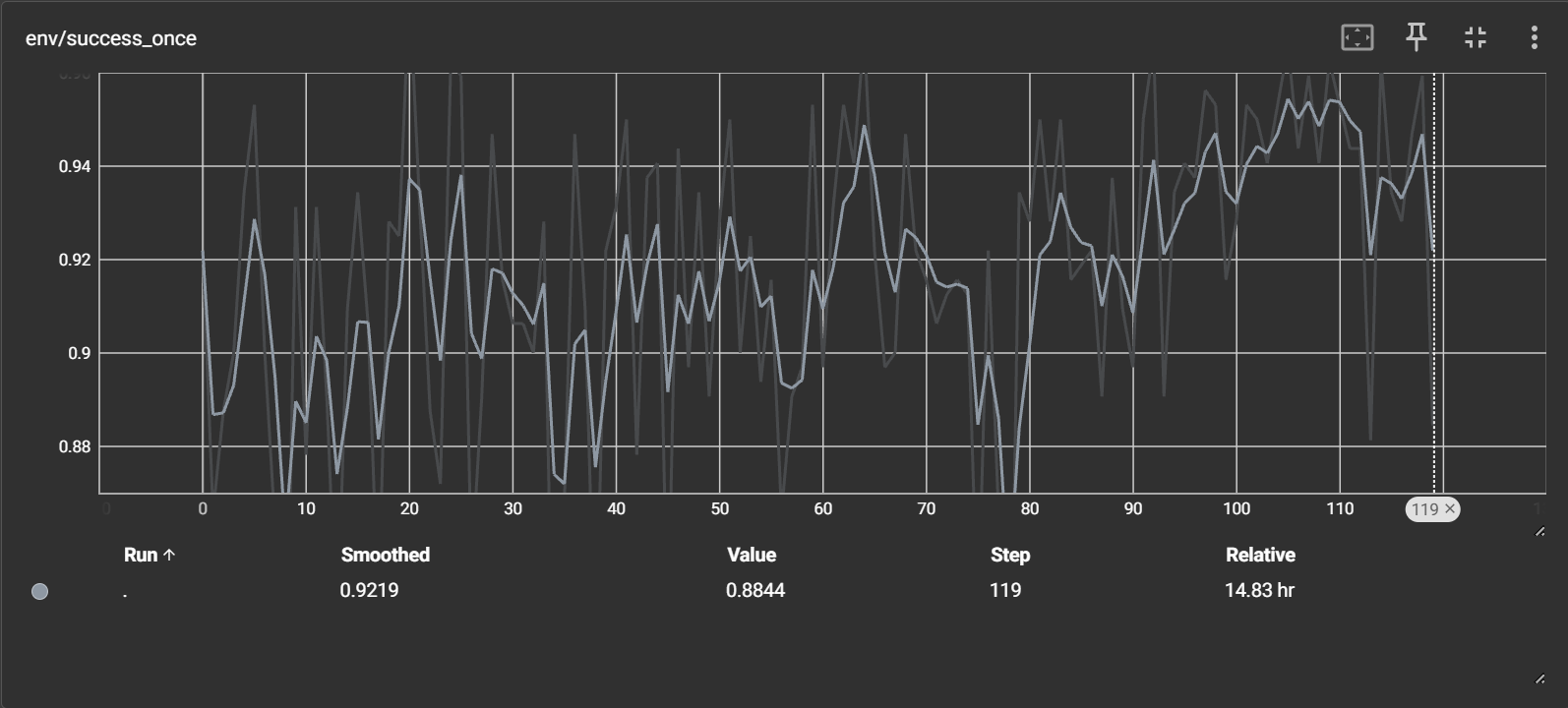
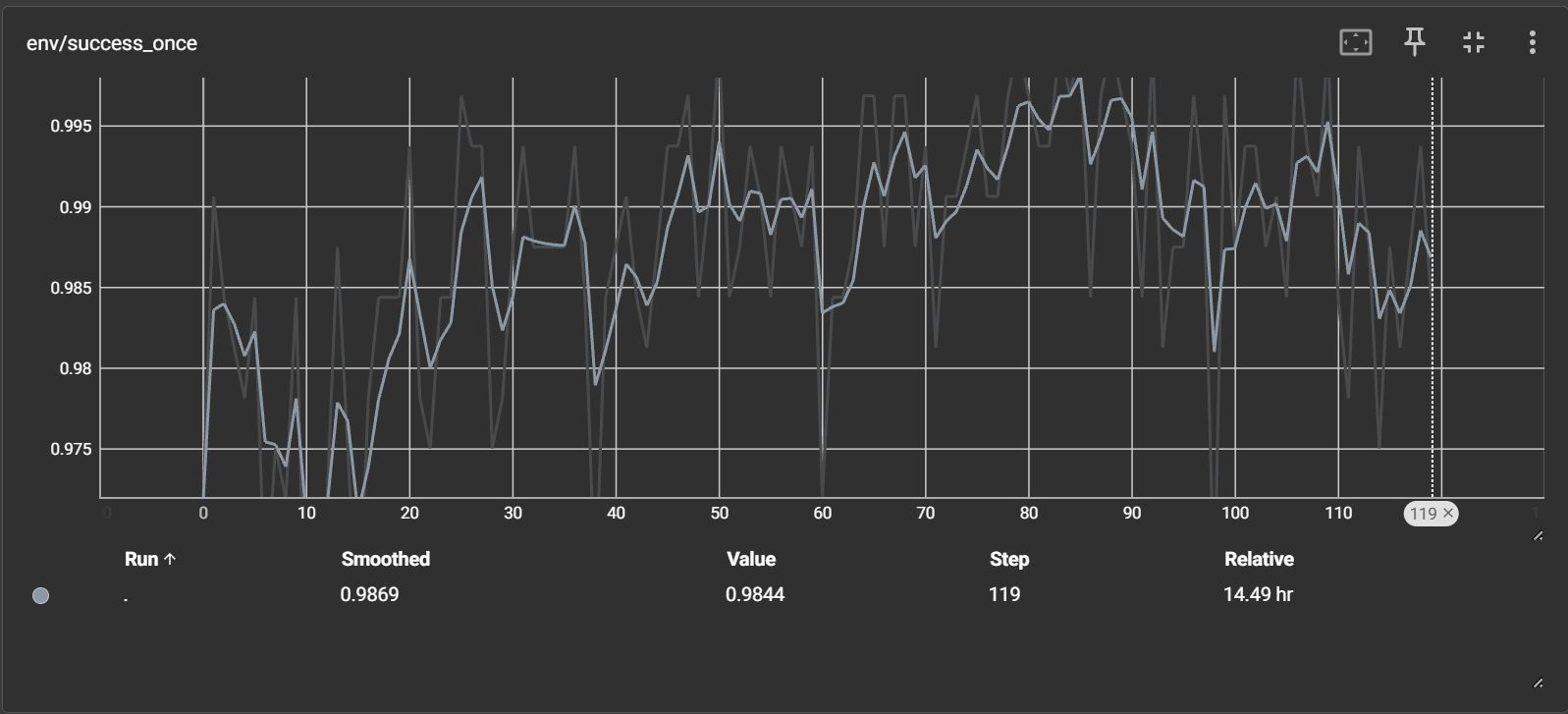
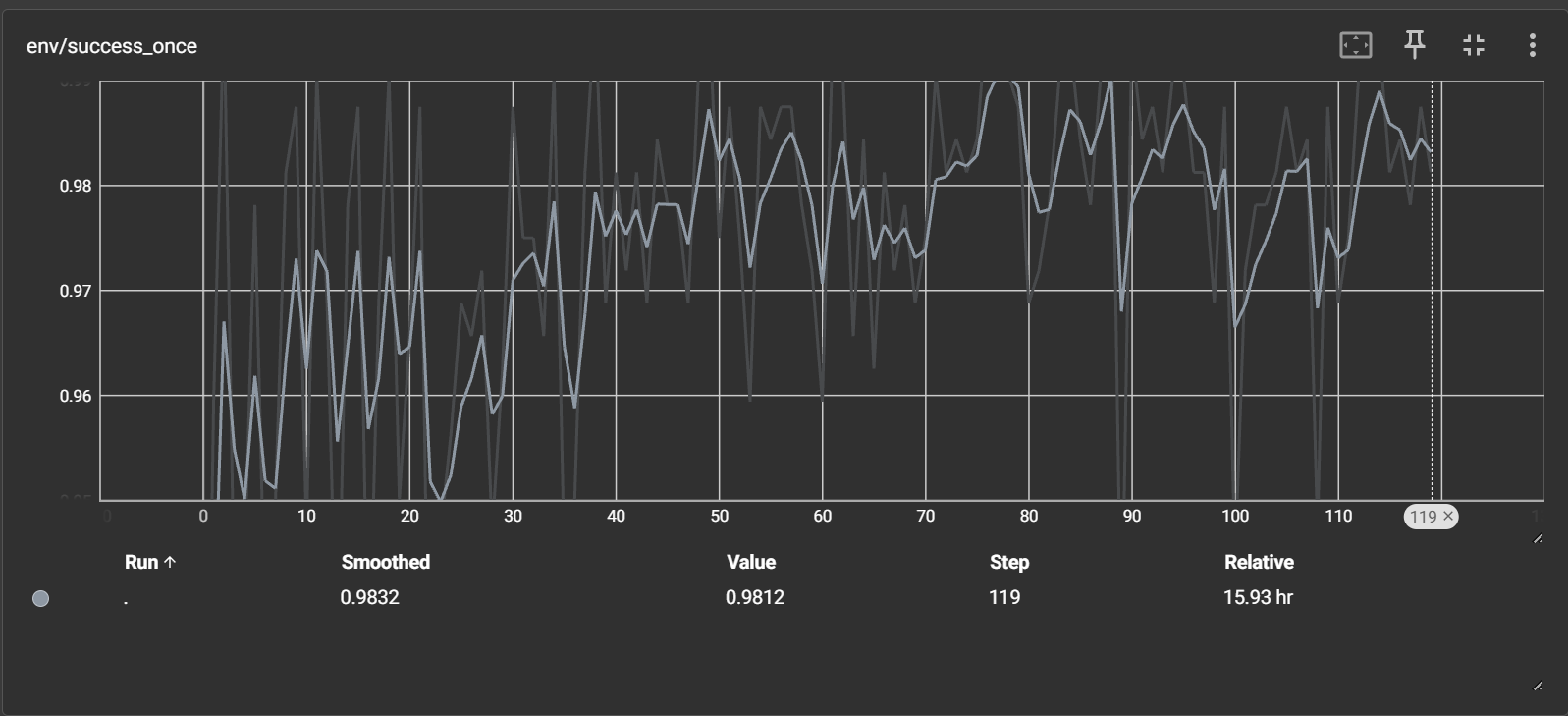
Visualization and Results#
Watch ``env/success_once`` for the task success rate. For every logged metric, see Training metrics.
Reference curves (using the model from LIBERO_BASELIEN_FORJINHUI_10K_QWENOFT):