Algorithms for Embodiment#
This category groups examples in which the training algorithm or recipe is the headline — independent of any single benchmark or model. They cover offline RL, imitation learning, hybrid sim-real co-training, and residual / noise-space policy steering.
Use this section when you are choosing how to train (PPO vs SAC vs IQL vs DAgger vs RECAP …) rather than what to train on or what model to fine-tune.
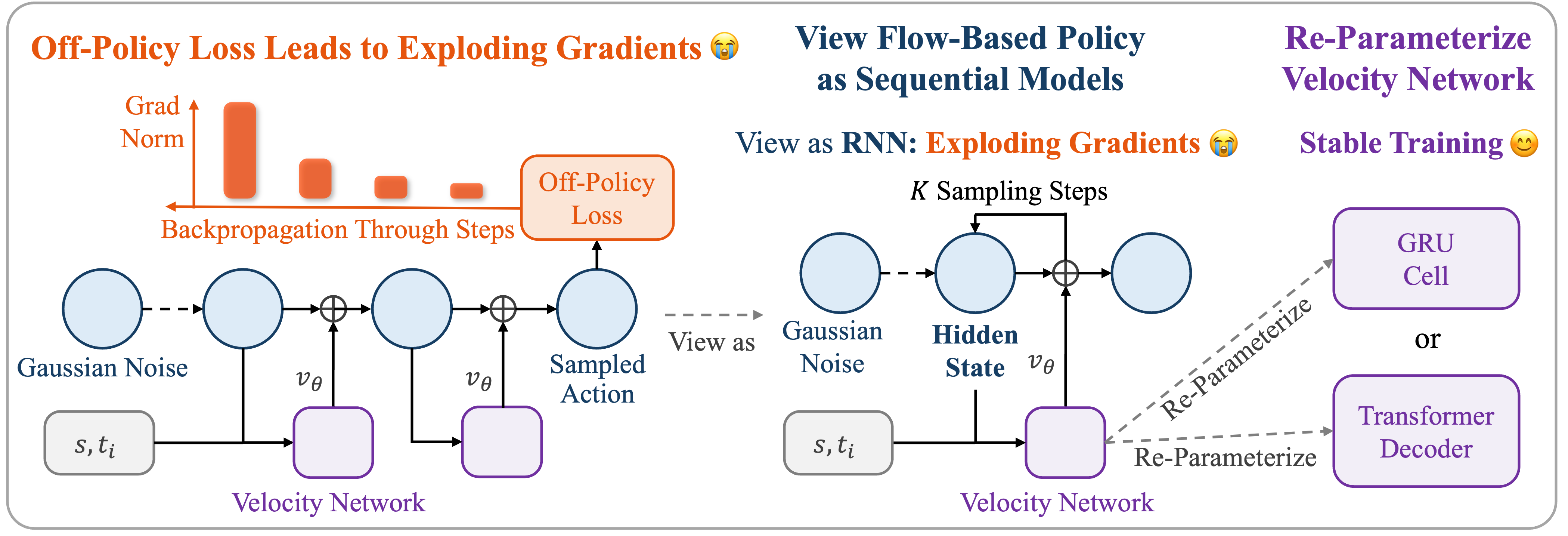
SAC-Flow Policy Training
Train a Flow Matching policy with SAC (Sim & Real)
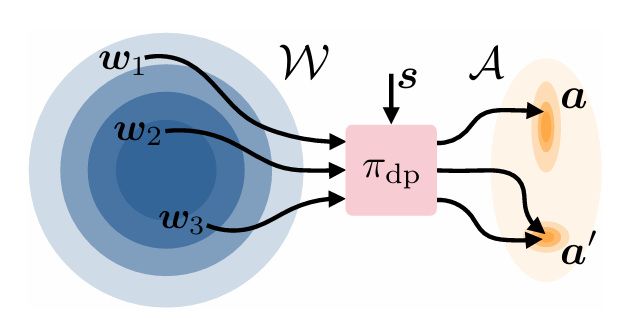
DSRL for Pi0
Steer a frozen Pi0 diffusion policy with lightweight SAC in noise space
DAgger for Embodied Policies
Guide online imitation learning with expert relabeling and replay-buffer updates
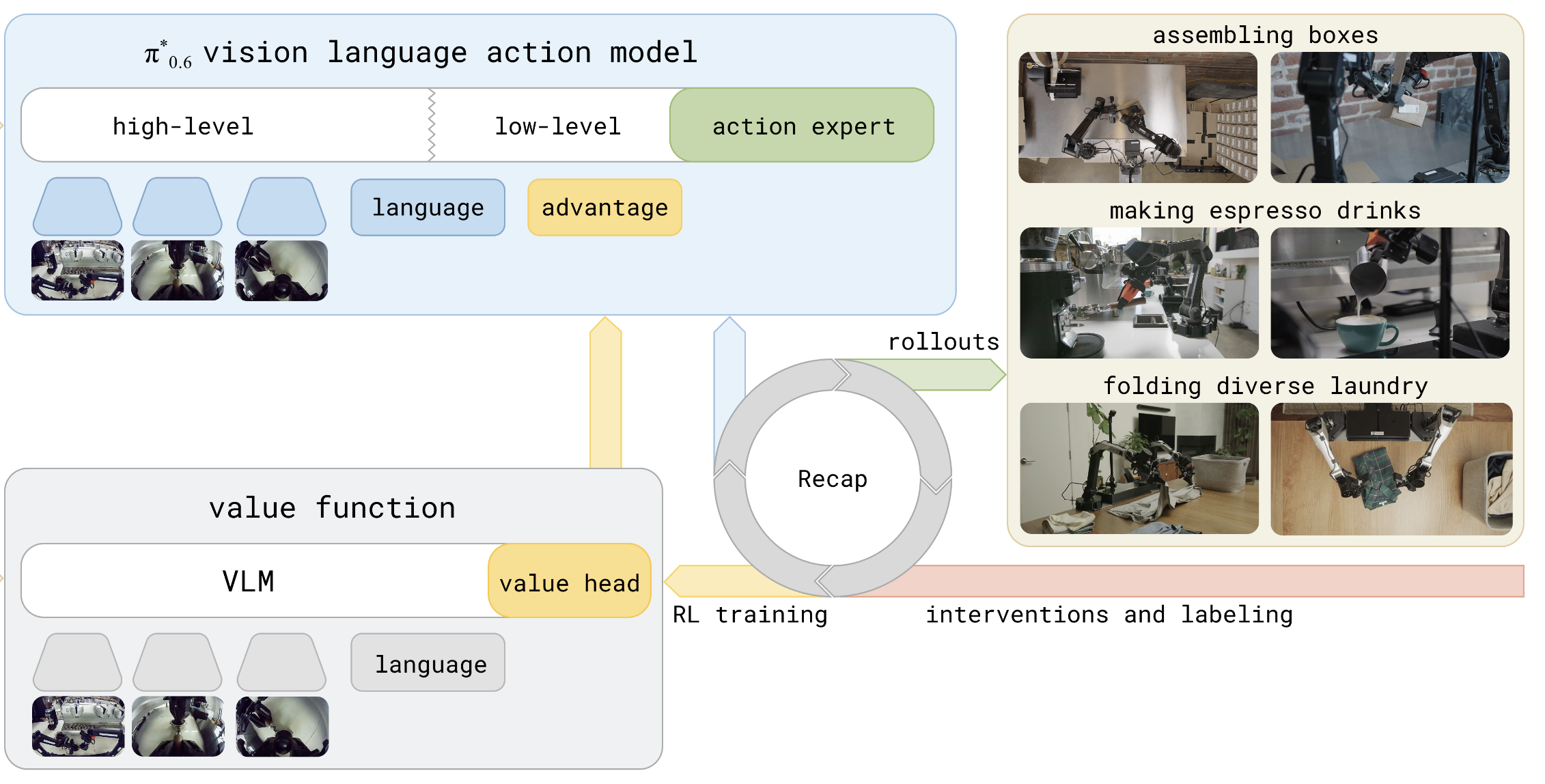
RECAP: Offline Advantage-Based Policy Optimization
Offline policy optimization via advantage-guided classifier-free guidance
Sim-Real Co-Training
PPO in sim + SFT on real data for better sim-to-real transfer

Offline RL with D4RL Benchmark
Support IQL offline training for D4RL scenarios