RL on Embodied Models#
This category groups examples in which the model or policy class is the headline. They show how to onboard a specific model family in RLinf — checkpoint loading, processor / config wiring, action head, lightweight MLP policies, and a reference RL fine-tuning recipe — independent of any single benchmark.
If you are starting from “I want to train or RL-fine-tune model X”, this is the right entry point. For benchmark-driven examples see RL with Embodied Simulators.
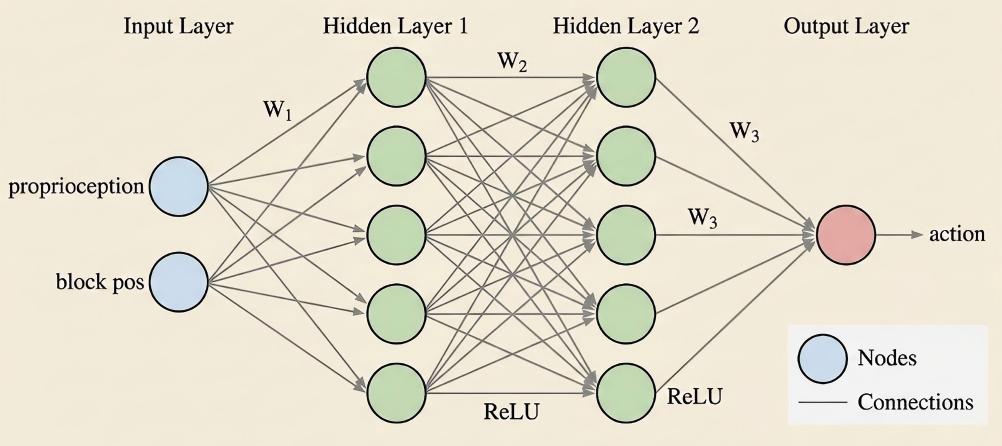
RL on MLP Policy
Train a lightweight MLP policy with PPO, SAC, or GRPO across simulation environments
RL on π₀ and π₀.₅ Models
Significant improvement in RL training on π₀ and π₀.₅
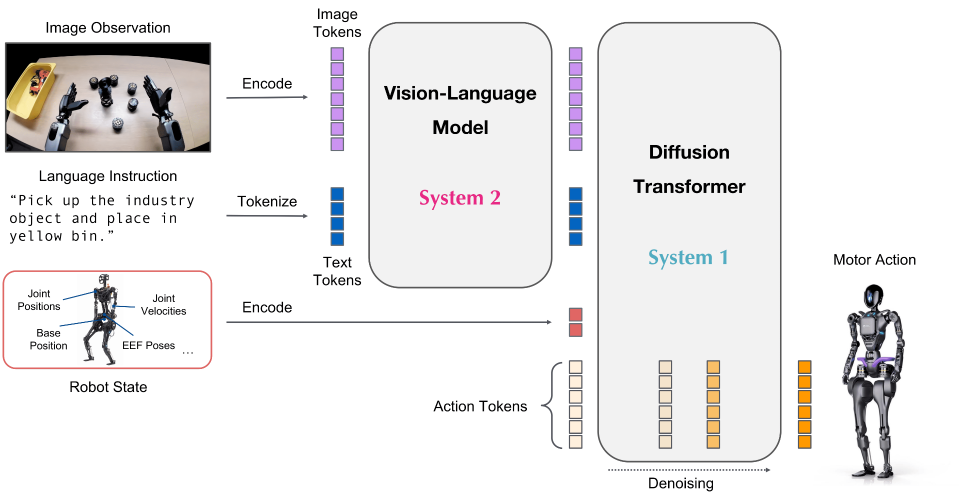
RL on GR00T Models
Support GR00T-N1.5, N1.6 and N1.7 RL fine-tuning.
RL with Lingbot-VLA Model
Support Lingbot-VLA + RoboTwin + GRPO training
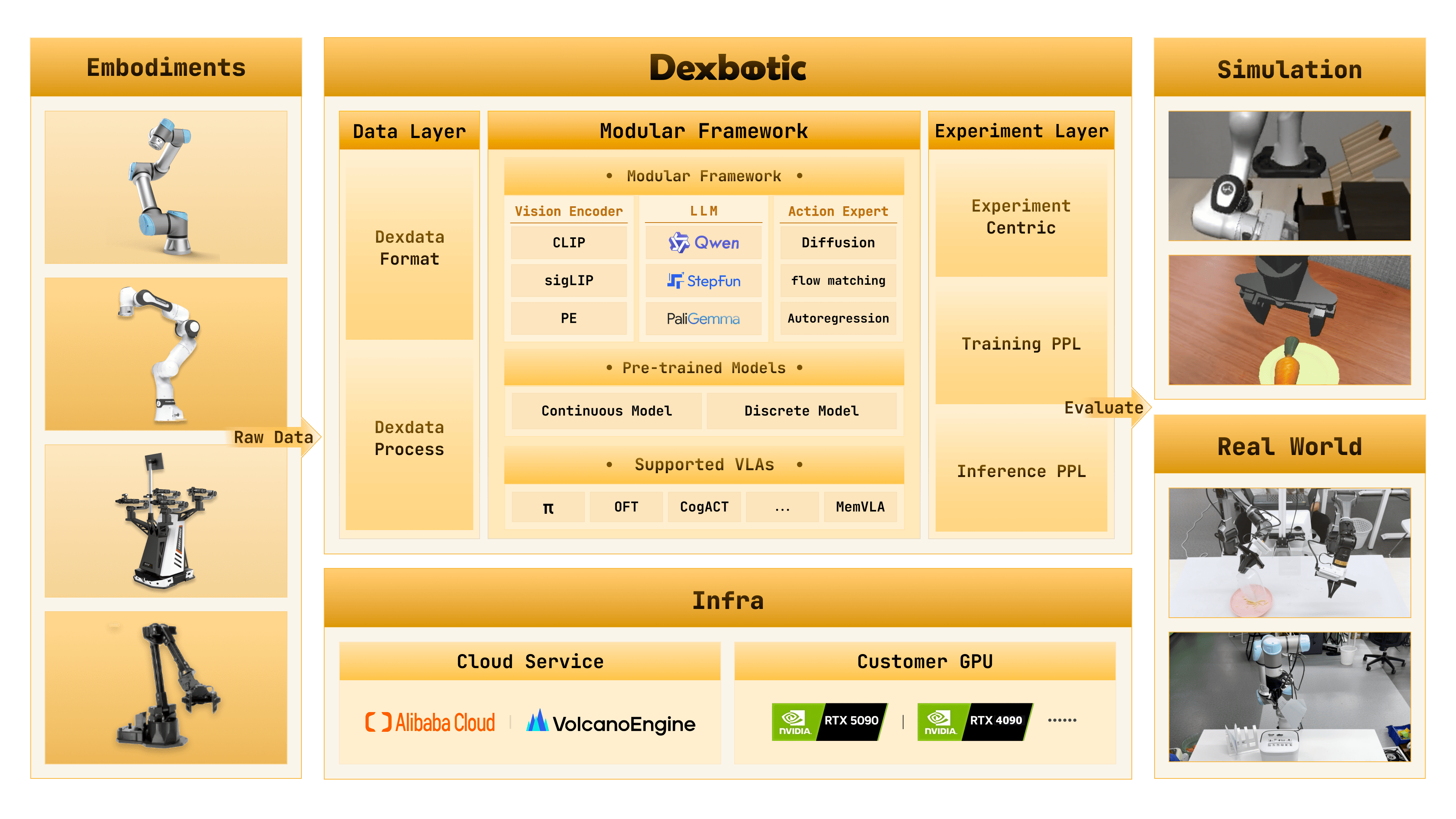
RL on Dexbotic Model
Dexbotic (π₀.₅-based) + LIBERO + PPO training
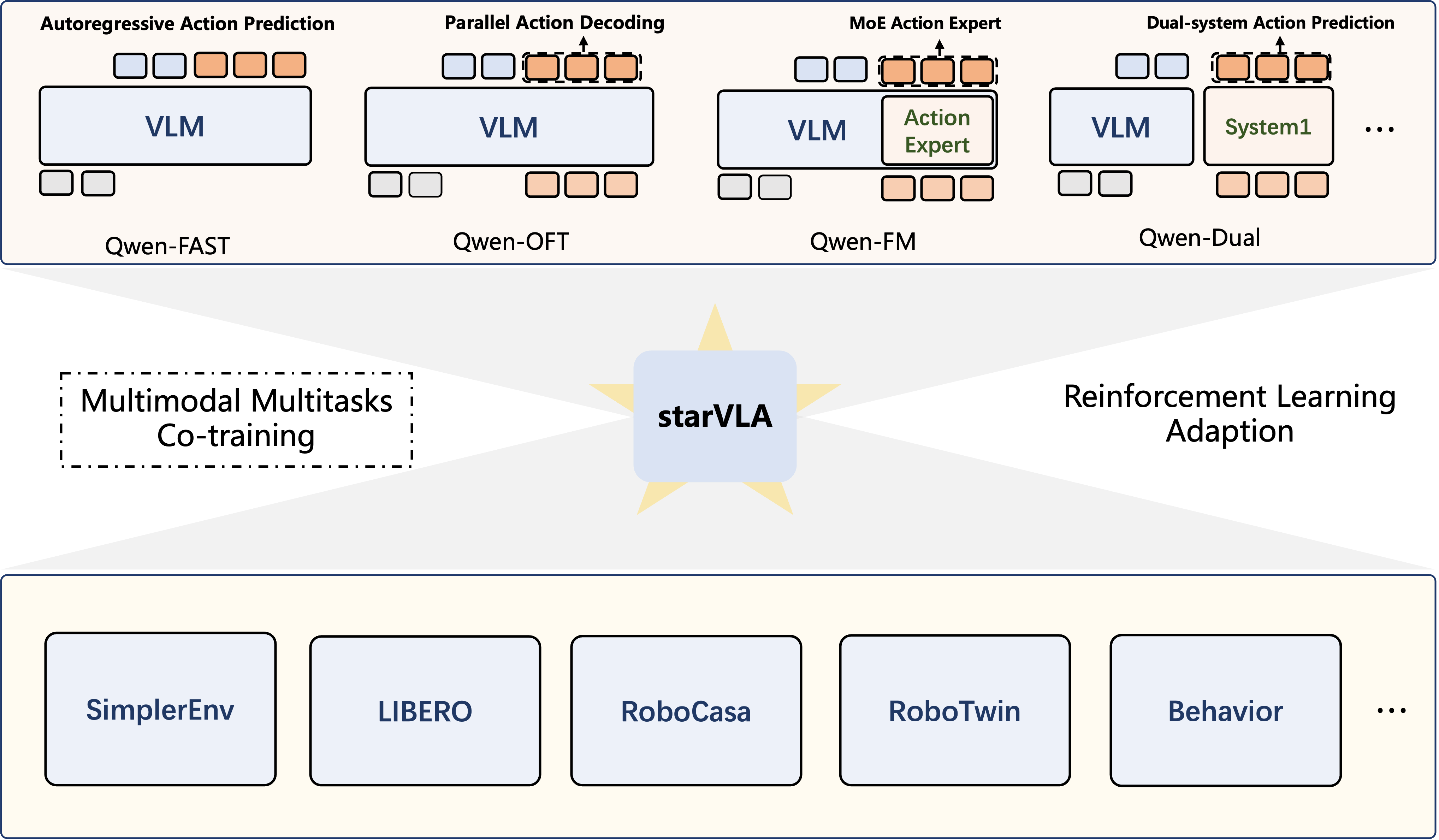
RL on StarVLA Models
StarVLA + LIBERO + GRPO embodied RL training
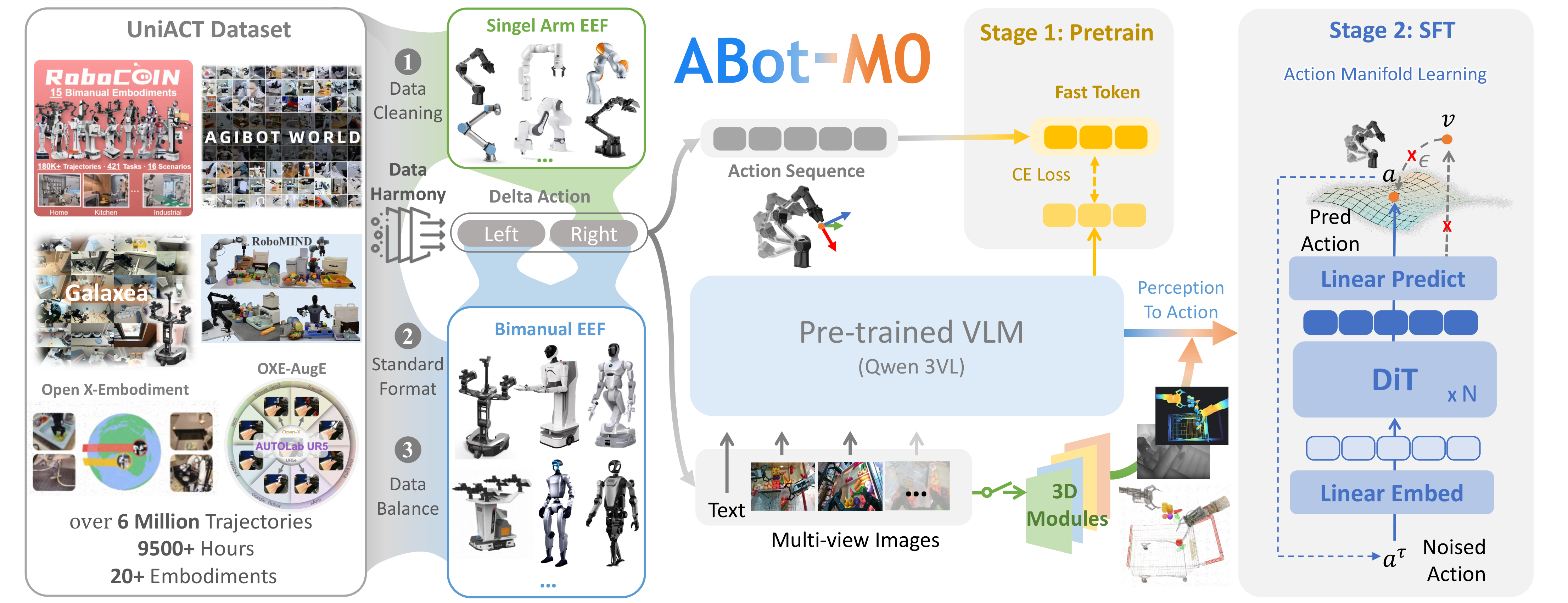
RL on ABot-M0 Model
ABot-M0 native integration with LIBERO-plus PPO training
RL with OpenSora World Model
Support OpenSora World Model + OpenVLA-OFT + GRPO training

RL with Wan World Model
Support Wan World Model + OpenVLA-OFT + GRPO training