SFT for VLA / WAM Models#
Supervised fine-tuning (SFT) is the standard cold-start step before embodied RL: a strong SFT checkpoint dramatically reduces RL exploration time and improves final policy quality. This category lists RLinf’s recipes for full-parameter and LoRA SFT on VLA / WAM models, plus VLM SFT for multimodal post-training.
After running SFT here, continue to RL on Embodied Models (model-centric RL) or RL with Embodied Simulators (benchmark-centric RL) to fine-tune the resulting checkpoint with RL.
OpenPI Supervised Fine-Tuning
Run full-parameter and LoRA SFT for OpenPI before RL fine-tuning
DreamZero Supervised Fine-Tuning
Full-parameter and mixture SFT for DreamZero (WAN2.1 / WAN2.2 backbones)
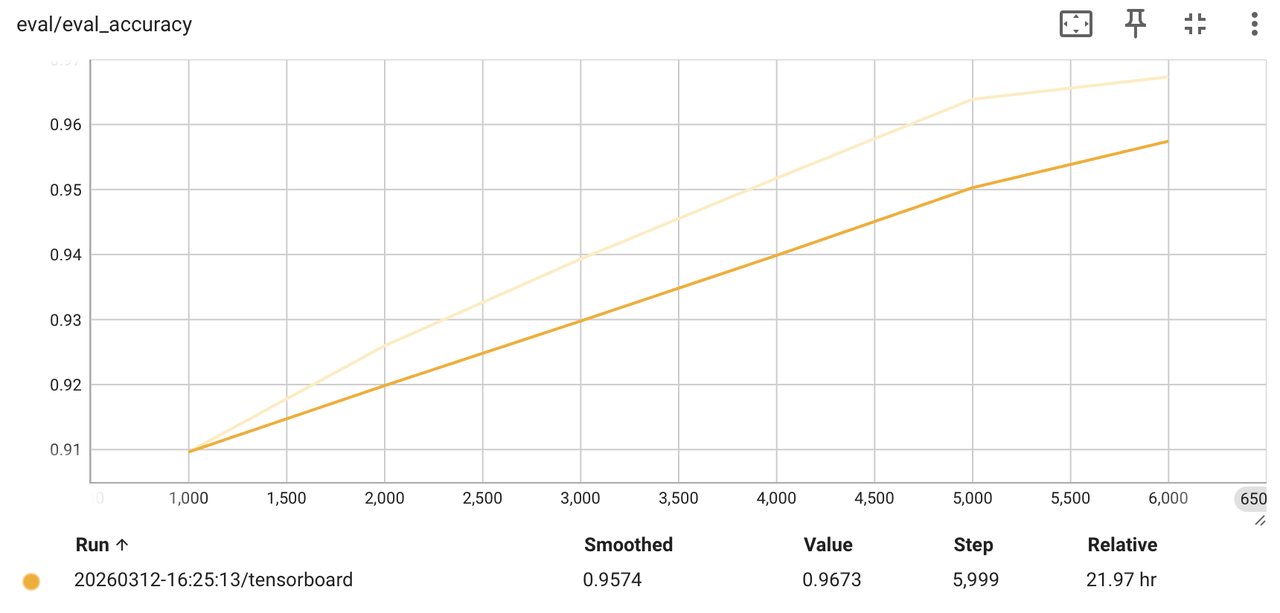
VLM Supervised Fine-Tuning
Run full-parameter SFT and evaluation for VLM models such as Qwen