RL with Embodied Simulators#
This category groups examples in which the simulator (or benchmark) is the headline. They show how to bring up RLinf on a specific simulation platform — environment installation, asset paths, observation/action spaces, and a reference RL recipe (typically PPO or GRPO with a VLA policy).
If you are starting from “I want to train on benchmark X”, this is the right entry point. For model-centric examples (pi₀, GR00T, …) see RL on Embodied Models. For real-robot setups, including Franka, see RL with Real-World Robots. For LIBERO setup on AMD ROCm or Ascend CANN accelerators, see the Supported Accelerators tutorial.
RL with ManiSkill Benchmark
ManiSkill + OpenVLA + PPO/GRPO achieves SOTA performance
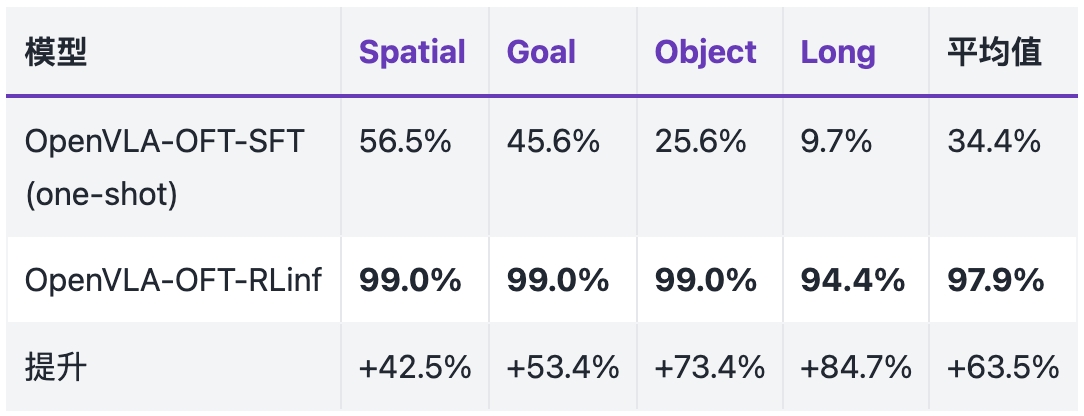
RL with LIBERO Benchmarks
OpenVLA-OFT + PPO/GRPO on LIBERO (99% success) and on the harder LIBERO-Pro / LIBERO-Plus suites

RL with Behavior Benchmark
Support BEHAVIOR + OpenVLA-OFT / π₀ / π₀.₅ + PPO training

RL with MetaWorld Benchmark
Support MetaWorld+π₀/π₀.₅+PPO/GRPO training

RL with IsaacLab Benchmark
Support IsaacLab+gr00t+PPO training
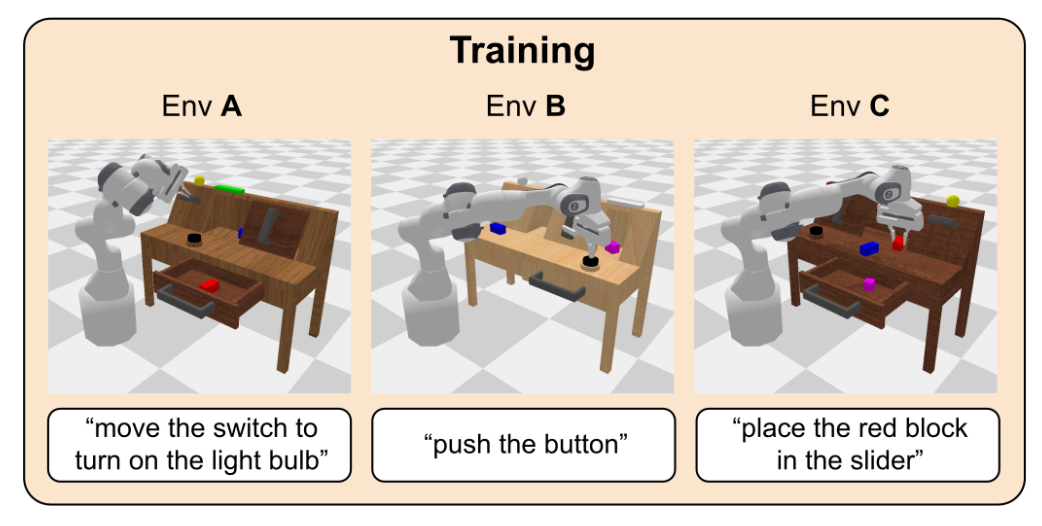
RL with CALVIN Benchmark
Support CALVIN+π₀/π₀.₅+PPO/GRPO training

RL with RoboCasa Benchmark
Support RoboCasa+π₀+GRPO training

RL with RoboTwin Benchmark
Supports RoboTwin + OpenVLA-OFT / π₀ / π₀.₅ + PPO / GRPO training

RL with RoboVerse Benchmark
Support RoboVerse + π₀.₅ + PPO training

RL with Franka-Sim Benchmark
Supports Franka-Sim + MLP/CNN + PPO/SAC training
RL with EmbodiChain
MLP + PPO on EmbodiChain gym tasks

RL with PolaRiS Benchmark
PolaRiS + OpenPI + PPO training

RL with GSEnv for Real2Sim2Real
Support GSEnv + π₀.₅ + PPO training

RL with Genesis Benchmark
MLP policy training on the Genesis simulation platform