RL on GR00T Models#
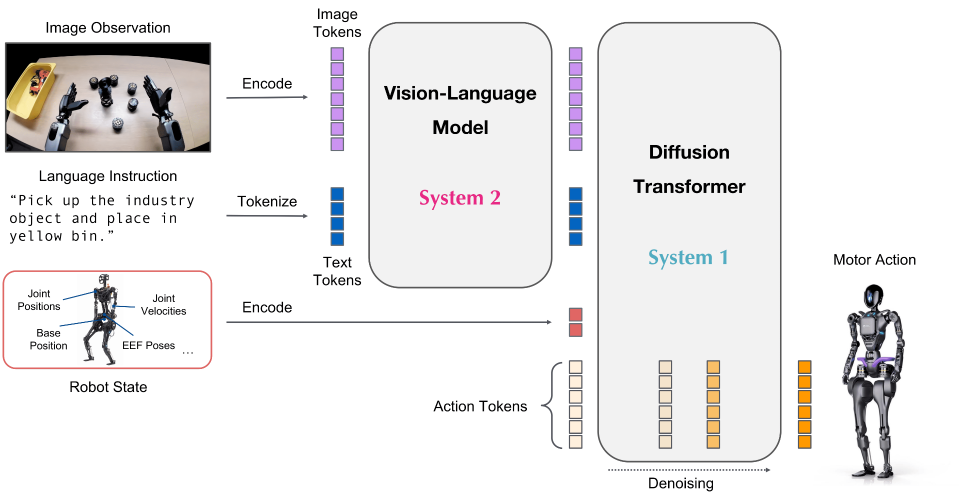
NVIDIA GR00T: a cross-embodiment VLA foundation model.#
Fine-tune GR00T models with reinforcement learning on LIBERO using RLinf — SFT cold-start, PPO training, evaluation, and visualization.
Note
RLinf supports GR00T-N1.5, GR00T-N1.6, and GR00T-N1.7. N1.6 introduced the Flow-Matching Action Head, FSDP-based training, and stronger cross-embodiment support. N1.7 further upgrades the official backbone to Cosmos-Reason2-2B / Qwen3-VL and expands the official universal state/action space. Version-specific differences are marked with N1.5 / N1.6 / N1.7 labels.
Overview#
Fine-tune GR00T (N1.5 / N1.6 / N1.7) on LIBERO with PPO (actor-critic).
LIBERO · IsaacLab
PPO
LIBERO Spatial · Object · Goal · Long
1 node · GPUs
run_embodiment.sh → watch env/success_once.Tasks#
Select the model page by matching the environment, task family, and config or checkpoint artifact.
Environment |
Task / Suite |
Config / Weights |
Focus |
|---|---|---|---|
LIBERO |
LIBERO-Spatial |
|
Flow-SDE PPO with GR00T-N1.x on spatial manipulation. |
LIBERO |
LIBERO-Object |
|
Object manipulation fine-tuning with GR00T. |
LIBERO |
LIBERO-Goal |
|
Goal-conditioned manipulation fine-tuning. |
LIBERO |
LIBERO-10 |
|
Long-horizon LIBERO training with GR00T. |
Observation and Action#
Field |
Description |
|---|---|
Observation |
Multi-view RGB images plus robot proprioception required by GR00T dataconfigs. |
Action |
Continuous action chunks generated by the GR00T policy. |
Reward |
LIBERO task success or simulator reward used by PPO. |
Prompt |
Natural-language task prompt provided with each LIBERO episode. |
Installation#
First, clone the RLinf repository:
# Mainland China users can use a mirror for faster cloning:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
Then set up the dependencies with one of the two methods below — a prebuilt
Docker image (recommended) or a custom environment. The general setup
(prerequisites, GPU drivers, the in-image switch_env helper, mirrors, and
troubleshooting) is documented once in Installation;
the commands in this recipe only differ in the Docker image tag and the
--env value.
Option 1: Docker image — image tag agentic-rlinf0.3-maniskill_libero:
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
# For mainland China users, you can use the following for better download speed:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-maniskill_libero
Please switch to the corresponding virtual environment via the built-in switch_env utility in the image:
N1.5:
source switch_env gr00t
N1.6:
source switch_env gr00t_n1d6
N1.7:
source switch_env gr00t_n1d7
Option 2: Custom Environment
N1.5:
# For mainland China users, you can add the `--use-mirror` flag to the install.sh command for better download speed.
bash requirements/install.sh embodied --model gr00t --env maniskill_libero
source .venv/bin/activate
N1.6:
# For mainland China users, you can add the `--use-mirror` flag to the install.sh command for better download speed.
bash requirements/install.sh embodied --model gr00t_n1d6 --env maniskill_libero
source .venv/bin/activate
N1.7:
# For mainland China users, you can add the `--use-mirror` flag to the install.sh command for better download speed.
bash requirements/install.sh embodied --model gr00t_n1d7 --env maniskill_libero
source .venv/bin/activate
Download the Model#
Before starting training, you need to download the corresponding pre-trained model.
N1.5: GR00T-N1.5 Few-Shot SFT Model Download
We currently support four LIBERO tasks: Spatial, Object, Goal, and Long.
# Method 1: Using git clone
git lfs install
git clone https://huggingface.co/RLinf/RLinf-Gr00t-SFT-Spatial
# Method 2: Using huggingface-hub
# For mainland China users, you can use the following for better download speed:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-Gr00t-SFT-Spatial --local-dir RLinf-Gr00t-SFT-Spatial
SFT model downloads for other tasks: - Libero-Object - Libero-Goal - Libero-Long
N1.6: GR00T-N1.6 SFT Model
We currently support LIBERO task Spatial and regard it as the RLinf demo for Gr00t N1.6
# Method 1: Using git clone
git lfs install
git clone https://huggingface.co/RLinf/RLinf-Gr00t-N1.6-SFT-Spatial
# Method 2: Using huggingface-hub
# For mainland China users, you can use the following for better download speed:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-Gr00t-N1.6-SFT-Spatial --local-dir RLinf/RLinf-Gr00t-N1.6-SFT-Spatial
N1.7: Temporary official release checkpoint usage
RLinf does not ship a dedicated RLinf-produced GR00T-N1.7 SFT checkpoint yet. In the current repository state, the maintained N1.7 RL example temporarily uses the official released LIBERO checkpoint as the task-checkpoint bootstrap.
In other words:
model_pathcurrently points to a locally unpacked officialnvidia/GR00T-N1.7-LIBEROcheckpoint, not to an RLinf-exported N1.7 SFT checkpoint produced by RLinf.backbone_model_pathpoints to a local snapshot ofCosmos-Reason2-2Bso actor, rollout, and processor can run fully offline.This is a practical temporary setup for RL integration and debugging.
This temporary setup is also consistent with the official N1.7 release notes:
Relative EEF Action Space: N1.7 adopts a relative end-effector action space shared across robot and human embodiments, which is one of the key reasons for its cross-embodiment generalization.
Human Video Pretraining: N1.7 is pretrained on 20K hours of EgoScale human video together with diverse robot demonstrations, so it can transfer manipulation priors from human video into robot control.
Key Changes from N1.6: N1.7 upgrades the VLM backbone to
Cosmos-Reason2-2B/ Qwen3-VL, simplifies the data-processing pipeline, and adds fuller ONNX / TensorRT export support.
Before RLinf ships its own N1.7 SFT checkpoint, you can use the following offline download pattern:
# For mainland China users, you can use the following for better download speed:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
# Download Cosmos-Reason2-2B backbone
uv run hf download nvidia/Cosmos-Reason2-2B \
--local-dir checkpoints/Cosmos-Reason2-2B
# Download GR00T-N1.7-LIBERO task checkpoint (libero_spatial minimum file set)
uv run hf download nvidia/GR00T-N1.7-LIBERO \
--include "libero_spatial/config.json" \
"libero_spatial/embodiment_id.json" \
"libero_spatial/model-*.safetensors" \
"libero_spatial/model.safetensors.index.json" \
"libero_spatial/processor_config.json" \
"libero_spatial/statistics.json" \
--local-dir checkpoints/GR00T-N1.7-LIBERO
The current example can run with this minimum file set. If experiment_cfg/metadata.json is also available in your local checkpoint directory, keep it there; RLinf prefers it when present, but can fall back to modality/config inference when it is missing.
Currently the maintained RLinf N1.7 RL example is LIBERO Spatial.
GR00T Core Design Concepts#
N1.5:
1. Modality Config
Modality Config is a critical design feature in GR00T-N1.5. By defining a unified dataset interface, it enables different robot configurations to utilize the same dataset. For example, a dual-arm dataset can be used to train a single-arm model through this innovative design.
1.1 Enhanced LeRobot Dataset
The LeRobot dataset contains a meta folder that records all dataset metadata.
GR00T-N1.5 further defines a modality.json file to determine the data interface of the dataset.
1.2 DataConfig Class
GR00T-N1.5 introduces the DataConfig class to describe all information needed for model training.
It decouples datasets from robot configurations, enabling model training across different robots without modifying data processing code.
1.3 Embodiment Tag
The Embodiment Tag is an enum value that determines which DataConfig to use during training. The model also adopts different state and action encoders/decoders based on this tag.
2. Fine-Tuning Guide
Based on the above design, before deploying GR00T-N1.5 in new environments beyond LIBERO, users need to fine-tune it. The fine-tuning guide can be found at GR00T official repo’s getting_started/finetune_new_embodiment.md.
After fine-tuning, GR00T-N1.5 generates an experiment_cfg/metadata.json file containing all modality configs and fine-tuned dataset statistics.
This file is essential for GR00T-N1.5 inference and RL post-training.
For more details, see GR00T official repo’s getting_started/GR00T_inference.ipynb.
N1.6:
1. Two-Stage Decoupled Training Paradigm
RLinf adopts a highly decoupled two-stage training architecture for GR00T-N1.6:
Stage 1 (Pure SFT): Uses
Pure SFT Modelmode. The model is completely detached from the physical simulation environment, relying solely on offline expert datasets for supervised fine-tuning.Stage 2 (PPO RL Alignment): Based on SFT convergence, loads the model into a FSDP-based distributed Actor for real-time interaction with the simulation environment.
2. Head-Only Fine-Tuning
To save memory while preventing “catastrophic forgetting”, the framework adopts a backbone-freezing strategy:
Backbone Freezing: Vision-language backbone parameters are strictly locked (
requires_grad=False).Action Head Focus: Only the action output head participates in gradient updates.
3. Flow-Matching Action Generation
The model generates high-frequency action chunks directly in continuous space through noise-adding and denoising flow-matching mechanisms (Flow-SDE / Diffusion).
Key configurations:
num_action_chunkscontrols prediction step length,denoising_stepscontrols denoising depth.
4. Cross-Embodiment Generalization
Embodiment Tag: Through configuration tags (e.g.,
ROBOCASA_PANDA_OMRON), the system dynamically adapts the corresponding state encoder and action space. Both single-arm manipulators and quadruped robots can reuse the same architecture.
5. FSDP Distributed Parallel Architecture
The underlying system has been restructured for the Actor node (
EmbodiedFSDPActor), which shards model weights, gradients, and optimizer states across GPU nodes.Given the significant increase in GR00T-N1.6 parameter scale, the Actor node has been fully restructured to break through the single-GPU memory bottleneck of traditional DDP.
After fine-tuning, the system generates metadata.json and other statistical files in the output directory, preserving key modality information for inference and deployment.
N1.7:
1. What’s New in official GR00T N1.7
GR00T N1.7 builds on N1.6 with a new VLM backbone and code-level improvements.
Relative EEF Action Space: N1.7 adopts a relative end-effector action space shared across robot and human embodiments. Representing actions as deltas from the current pose, instead of absolute targets, improves generalization and is a key reason for its cross-embodiment performance.
Human Video Pretraining: N1.7 is pretrained on 20K hours of EgoScale human video together with diverse robot demonstrations. Because the relative EEF action representation is shared across human and robot data, manipulation priors learned from human video can transfer more directly to robot control.
2. Key Changes from N1.6
The official backbone is upgraded to
nvidia/Cosmos-Reason2-2Bwith a Qwen3-VL style architecture, replacing the Eagle backbone used in N1.6.The official
processing_gr00t_n1d7.pypath simplifies the data-processing pipeline compared with the older N1.6 stack.The official N1.7 stack also expands ONNX / TensorRT export support.
The official N1.7 model config raises the default universal limits to
max_state_dim=132,max_action_dim=132, andaction_horizon=40.
3. Current checkpoint strategy in RLinf
RLinf does not yet provide a repository-produced N1.7 SFT checkpoint for this RL example.
The current maintained example therefore temporarily uses the official released
GR00T-N1.7-LIBERO/libero_spatialcheckpoint asmodel_path.
4. RLinf N1.7 Interface Adaptation
The current raw LIBERO state in RLinf is 8-dim before conversion, while the official N1.7 model uses a larger universal state/action representation internally.
The current LIBERO example uses
embodiment_tag: libero_simand applies the LIBERO gripper convention in the shared environment action utilities.
5. Checkpoint and Processor Contract
RLinf loads the official processor directly from the checkpoint directory.
When running in offline or mirrored environments,
backbone_model_pathcan redirect the official backbone id to a localCosmos-Reason2-2Bsnapshot.The current temporary official-release download command may omit
experiment_cfg/metadata.json; that is acceptable for now because RLinf has a fallback path, but keeping metadata is still recommended when available.
6. RL Training Contract in This Repository
The maintained RLinf N1.7 RL example is
examples/embodiment/config/libero_spatial_ppo_gr00t_n1d7.yaml.The current RL setup uses PPO with
algorithm.loss_type: actor_critic, soactor.model.add_value_headmust beTrueduring training.The repository’s validated LIBERO example uses
num_action_chunks: 16anddenoising_steps: 4.
Run It#
1. Key Cluster Configuration
cluster:
num_nodes: 1
component_placement:
env,rollout,actor: all
You can configure the placement to share all GPUs among env, rollout, and actor components.
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout: 4-7
actor: 0-7
rollout:
pipeline_stage_num: 2
You can flexibly configure GPU counts for env, rollout, and actor components, and enable pipelining between rollout and env via pipeline_stage_num.
cluster:
num_nodes: 1
component_placement:
env: 0-1
rollout: 2-5
actor: 6-7
You can also fully separate components, each using dedicated GPUs without offloading.
2. Key Model Parameters
N1.5:
model:
num_action_chunks: 5
denoising_steps: 4
rl_head_config:
noise_method: "flow_sde"
noise_level: 0.5
disable_dropout: True
You can adjust noise_level and denoising_steps to control noise intensity and flow-matching steps.
num_action_chunks determines the number of future steps to use for forward simulation.
GR00T-N1.5’s action head contains dropout layers that interfere with log-probability calculations, so disable_dropout must be set to True to replace them with identity layers.
Use noise_method to select different noise injection methods. Two options are available:
flow-sde and
flow-noise.
N1.6:
Actor Model & Action Head Configuration
model:
model_type: "gr00t_n1d6"
add_value_head: True # RL critical: dynamically inject value network for advantage prediction
num_action_chunks: 16 # Number of future action steps predicted per inference
denoising_steps: 4 # Controls flow-matching denoising steps
FSDP Sharding Strategy
fsdp_config:
wrap_policy:
transformer_layer_cls_to_wrap:
- "Qwen3DecoderLayer"
- "Siglip2EncoderLayer"
N1.7:
Actor Model & Action Head Configuration
model:
model_type: "gr00t_n1d7"
add_value_head: True
num_action_chunks: 16
denoising_steps: 4
Runtime Path Configuration
model:
model_path: "/path/to/GR00T-N1.7-LIBERO/libero_spatial"
backbone_model_path: "/path/to/Cosmos-Reason2-2B"
PPO & Optimizer Hyperparameters
algorithm:
adv_type: gae
clip_ratio_high: 0.2
gamma: 0.99
gae_lambda: 0.95
optim:
lr: 5.0e-6
value_lr: 1.0e-4
clip_grad: 1.0
3. Configuration Files
N1.5:
GR00T-N1.5 + PPO + Libero-Spatial:
examples/embodiment/config/libero_spatial_ppo_gr00t.yamlGR00T-N1.5 + PPO + Libero-Object:
examples/embodiment/config/libero_object_ppo_gr00t.yamlGR00T-N1.5 + PPO + Libero-Goal:
examples/embodiment/config/libero_goal_ppo_gr00t.yamlGR00T-N1.5 + PPO + Libero-Long:
examples/embodiment/config/libero_10_ppo_gr00t.yaml
N1.6:
GR00T-N1.6 + PPO + Libero-Spatial:
examples/embodiment/config/libero_spatial_ppo_gr00t_n1d6.yaml
Update the SFT model path:
model:
model_path: "/path/to/RLinf-Gr00t-N1.6-RL-Spatial"
N1.7:
GR00T-N1.7 + PPO + Libero-Spatial:
examples/embodiment/config/libero_spatial_ppo_gr00t_n1d7.yaml
Update the SFT model path:
model:
model_path: "/path/to/GR00T-N1.7-LIBERO/libero_spatial"
backbone_model_path: "/path/to/Cosmos-Reason2-2B"
4. Launch Commands
N1.5:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_gr00t
bash examples/embodiment/run_embodiment.sh libero_object_ppo_gr00t
bash examples/embodiment/run_embodiment.sh libero_goal_ppo_gr00t
bash examples/embodiment/run_embodiment.sh libero_10_ppo_gr00t
N1.6:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_gr00t_n1d6
N1.7:
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_gr00t_n1d7
Visualization and Results#
1. TensorBoard Logs
# Launch TensorBoard
tensorboard --logdir ./logs --port 6006
2. Key Metrics
Watch ``env/success_once`` for the task success rate. For every logged metric, see Training metrics.
3. Video Generation
video_cfg:
save_video: True
info_on_video: True
video_base_dir: ${runner.logger.log_path}/video/train
4. WandB Integration
runner:
task_type: embodied
logger:
log_path: "../results"
project_name: rlinf
experiment_name: "libero_spatial_ppo_gr00t"
logger_backends: ["tensorboard", "wandb"] # tensorboard, wandb, swanlab
LIBERO Results
N1.5:
Model |
Spatial |
Object |
Goal |
Long |
Average |
Δ Avg. |
|---|---|---|---|---|---|---|
GR00T (few-shot) |
52.5% |
— |
||||
+PPO |
89.5% |
+37.0% |
We would like to point out that the results presented above utilize the identical hyperparameter settings as \(\pi_0\). These findings primarily serve to demonstrate the broad applicability and inherent robustness of the proposed RL training framework. Further optimization through parameter tuning is likely to yield enhanced model performance.
N1.6:

GR00T-N1.6 SFT + PPO Accuracy Curve on LIBERO_Spatial
N1.7:
Model |
Spatial |
|---|---|
GR00T-N1.7 PPO |
|