RL with Franka-Sim Benchmark#

Franka-Sim assets from the RLinf SERL fork.#
Franka-Sim is a lightweight Franka Panda simulation environment built from the SERL stack. You’ll use RLinf to train either an MLP policy with PPO on state observations or a CNN policy with asynchronous SAC on RGB observations.
Overview#
Train a Franka pick-cube policy with either state-only or vision observations.
MLP · CNN
PPO · SAC
PickCube state · vision
1 node · 1 GPU
env/success_once.Tasks#
Task |
Description |
|---|---|
|
State-observation pick-cube task for the MLP + PPO recipe. |
|
RGB-observation pick-cube task for the CNN + asynchronous SAC recipe. |
Observation and Action#
Field |
Specification |
|---|---|
Observation |
|
Action |
4-dim continuous action: 3D end-effector position delta plus gripper control. |
Reward |
Dense task-progress reward. |
Prompt |
Not used by the state MLP recipe; vision policies consume task-conditioned observations from the env wrapper. |
Installation#
First, clone the RLinf repository:
# Mainland China users can use a mirror for faster cloning:
# git clone https://ghfast.top/github.com/RLinf/RLinf.git
git clone https://github.com/RLinf/RLinf.git
cd RLinf
Then set up the dependencies with one of the two methods below — a prebuilt
Docker image (recommended) or a custom environment. The general setup
(prerequisites, GPU drivers, the in-image switch_env helper, mirrors, and
troubleshooting) is documented once in Installation;
the commands in this recipe only differ in the Docker image tag and the
--env value.
Docker image
docker run -it --rm --gpus all \
--shm-size 32g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
rlinf/rlinf:agentic-rlinf0.3-frankasim
# For mainland China users:
# docker.1ms.run/rlinf/rlinf:agentic-rlinf0.3-frankasim
Switch to the virtual environment inside the image:
source switch_env openvla
Custom environment
Install Franka-Sim dependencies:
# Mainland China users can add --use-mirror.
bash requirements/install.sh embodied --model openvla --env frankasim
source .venv/bin/activate
Download the Model#
Skip this section for the MLP + PPO recipe. For the CNN + SAC recipe, download the ResNet checkpoint:
cd /path/to/save/model
git lfs install
git clone https://huggingface.co/RLinf/RLinf-ResNet10-pretrained
# Or use huggingface-hub:
# export HF_ENDPOINT=https://hf-mirror.com
pip install huggingface-hub
hf download RLinf/RLinf-ResNet10-pretrained --local-dir RLinf-ResNet10-pretrained
Then set the same checkpoint path for rollout and actor in
examples/embodiment/config/frankasim_sac_cnn_async.yaml:
rollout:
model:
model_path: /path/to/RLinf-ResNet10-pretrained
actor:
model:
model_path: /path/to/RLinf-ResNet10-pretrained
Run It#
Pick one recipe and launch training:
Recipe |
Config |
Entrypoint |
Command suffix |
|---|---|---|---|
MLP + PPO |
|
|
|
CNN + SAC |
|
|
|
# State-observation PPO recipe
bash examples/embodiment/run_embodiment.sh frankasim_ppo_mlp
# Vision SAC recipe
bash examples/embodiment/run_async.sh frankasim_sac_cnn_async
What this does:
Starts the selected embodied training entrypoint.
Creates Ray workers for the actor, rollout, and Franka-Sim env components.
Runs rollouts, computes task rewards, and updates the selected policy.
Note
Both reference configs run on GPU 0. Tune cluster.component_placement,
env.train.total_num_envs, and batch sizes if you move to a larger machine.
Visualization and Results#
Launch TensorBoard from the RLinf repo root:
tensorboard --logdir ../results --port 6006
The key signal is env/success_once. For every logged metric, see
Training metrics.
Enable video when you want rollout videos:
env:
eval:
video_cfg:
save_video: True
video_base_dir: ${runner.logger.log_path}/video/eval
Recipe |
Reported Behavior |
|---|---|
CNN + asynchronous SAC |
Learns a stable grasping strategy within about one hour in the simulation setup used for the original run. |
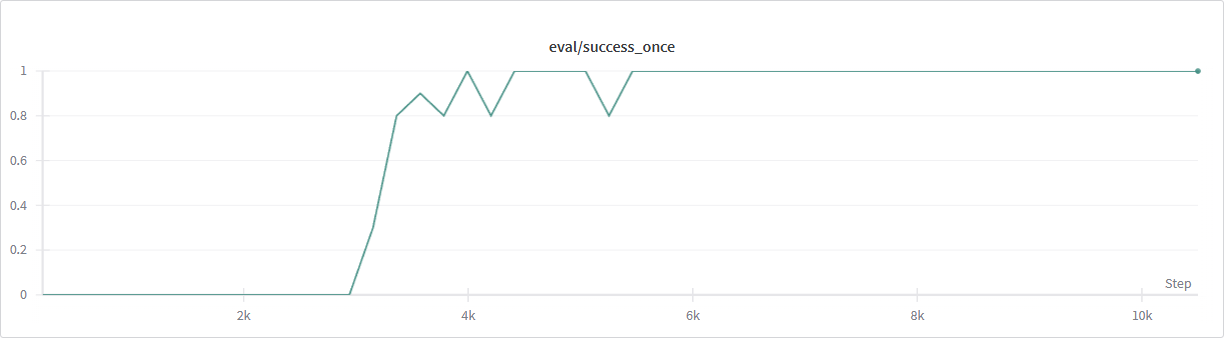
Franka-Sim asynchronous SAC + CNN success-rate curve.#