rStar2的强化学习训练#
使用本配方复现 rStar2-Agent: Agentic Reasoning Technical Report 的多轮工具调用实验,通过强化学习训练大语言模型调用代码运行工具回答问题。
概述#
使用本配方复现 rStar2 风格的智能体推理,包含代码执行工具与 Megatron 训练。
Qwen2.5-7B-Instruct
带工具调用的多轮强化学习
Code Judge server 与 Math-Verify reward
参考运行使用 8×H100
环境#
RLinf环境#
RLinf 环境配置参照 RLinf Installation。
Code judge运行环境#
我们使用 rStar2 示例中的 code judge 工具,安装过程参考 rStar2 & veRL-SGLang
cd examples/agent/rstar2
# install code judge
sudo apt-get update -y && sudo apt-get install redis -y
git clone https://github.com/0xWJ/code-judge
pip install -r code-judge/requirements.txt
pip install -e code-judge
# install rstar2_agent requirements
pip install -r requirements.txt
cd code-judge
Code Judge 服务器设置#
rStar2-Agent 使用 Code Judge 作为工具调用服务器来执行模型生成的 Python 代码。
1. 启动 Redis 服务器
sudo apt-get update -y && sudo apt-get install redis -y
redis-server --daemonize yes --protected-mode no --bind 0.0.0.0
2. 启动 Code Judge Server
# Start the main server (master node only)
# Environment variables can be configured as per: https://github.com/0xWJ/code-judge/blob/main/app/config.py
# Replace $WORKSPACE and $MASTER_ADDR with your actual paths
tmux new-session -d -s server \
'cd $WORKSPACE/examples/agent/rstar2/code-judge && \
MAX_EXECUTION_TIME=4 \
REDIS_URI="redis://$MASTER_ADDR:6379" \
RUN_WORKERS=0 \
uvicorn app.main:app --host 0.0.0.0 --port 8000 --workers 16 \
2>&1 | tee server.log'
3. 启动 Code Judge Workers
# Launch workers (can be deployed on multiple nodes for increased parallelism)
# Adjust MAX_WORKERS based on your CPU count per node
tmux new-session -d -s worker \
'cd $WORKSPACE/examples/agent/rstar2/code-judge && \
MAX_EXECUTION_TIME=4 \
REDIS_URI="redis://$MASTER_ADDR:6379" \
MAX_WORKERS=64 \
python run_workers.py \
2>&1 | tee worker.log'
Reward计算工具#
我们使用 Math-Verify 辅助进行 reward 计算,需通过 pip 安装
pip install math-verify
我们同时使用了简单规则进行reward计算,以确保reward计算的正确性, 计算需安装依赖。
pip install sympy
pip install pylatexenc
在8*H100上训练#
通过 examples/agent/rstar2/data_process/process_train_dataset.py 下载训练集,并将路径写入 examples/agent/rstar2/config/rstar2-qwen2.5-7b-megatron.yaml
data:
# ……
train_data_paths: ["/path/to/train.jsonl"]
val_data_paths: ["/path/to/train.jsonl"]
修改 examples/agent/rstar2/config/rstar2-qwen2.5-7b-megatron.yaml 中 rollout.model.model_path 的路径
rollout:
group_name: "RolloutGroup"
gpu_memory_utilization: 0.5
model:
model_path: /path/to/model/Qwen2.5-7B-Instruct
model_type: qwen2.5
由于 down sample 逻辑不适配目前 inference 逻辑,recompute_logprobs 应当设置为 False
algorithm:
# ……
recompute_logprobs: False
shuffle_rollout: False
运行#
运行 examples/agent/rstar2/run_rstar2.sh 启动训练。
可视化与结果#
下面展示 RLinf 与 Verl 的 reward 曲线和 response 长度曲线对比。
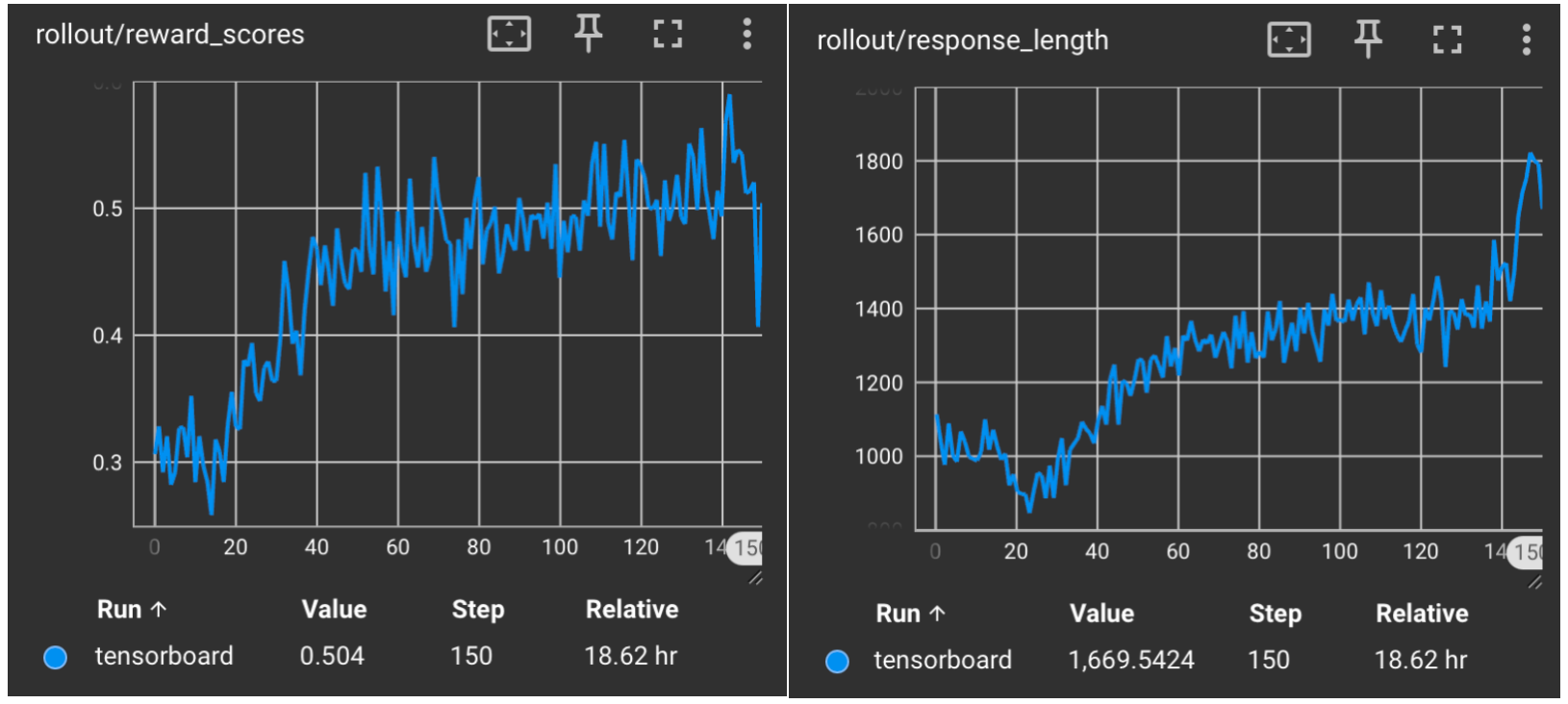
Qwen2.5-7B-Instruct in RLinf#
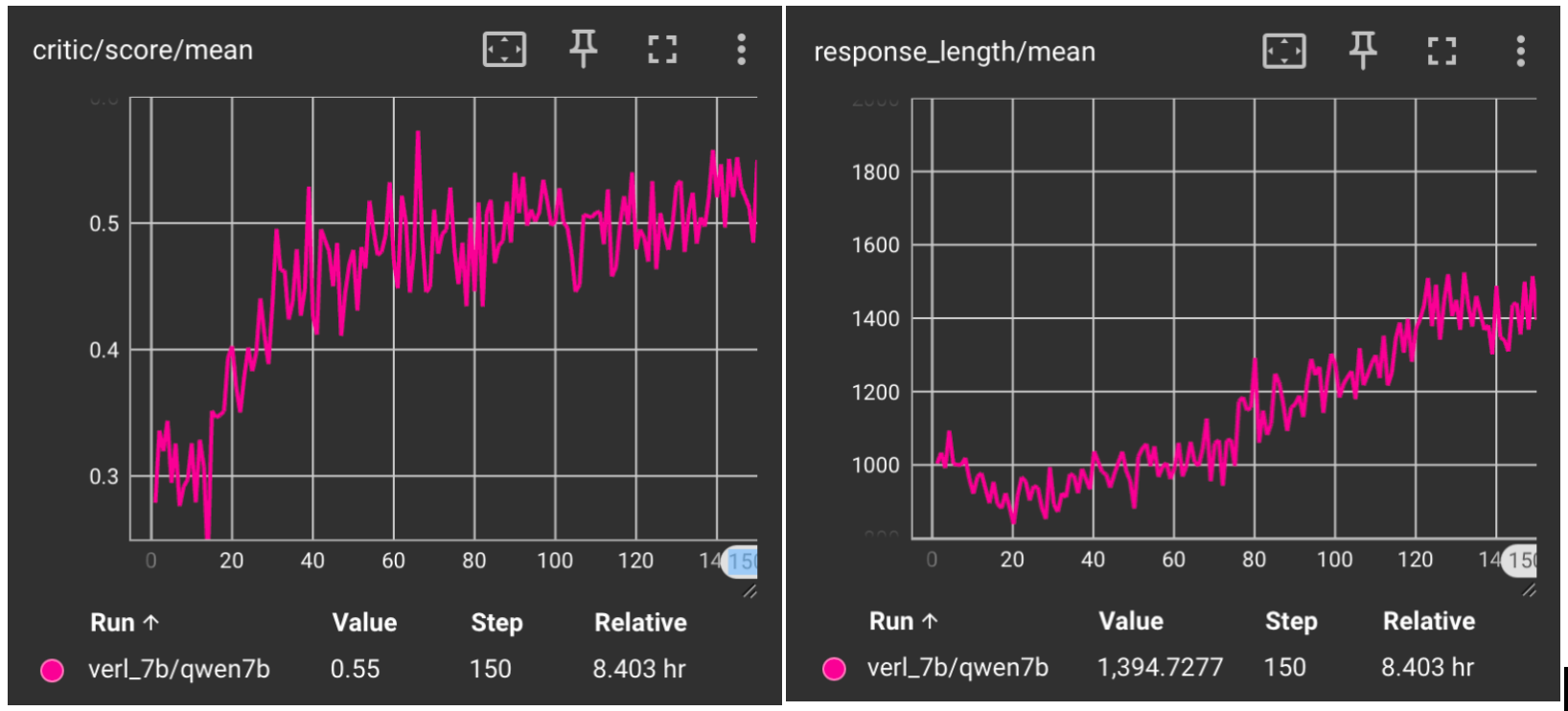
Qwen2.5-7B-Instruct in Verl#
* 我们使用默认配置对模型进行了 150 步重训,以和Verl的效果对齐。
References#
rStar2 & veRL-SGLang: volcengine/verl#3397