Search-R1的强化学习训练#
使用本配方复现 Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning 的搜索增强推理实验,通过强化学习训练大语言模型调用搜索工具回答问题。
概述#
使用本配方结合本地 wiki 检索服务训练搜索增强推理模型。
Qwen2.5-3B-Instruct
带搜索工具调用的多轮强化学习
FAISS 或 Qdrant 本地 wiki server
参考运行使用 8×H100
环境#
RLinf环境#
RLinf 环境配置参照 RLinf Installation。
Local Wiki Server运行环境#
我们使用search-R1示例中的local retrieve server,通过conda安装faiss,详细文档见SearchR1,安装过程参考Search-R1 & veRL-SGLang,同样使用conda来配置环境
conda create -n retriever python=3.10 -y
conda activate retriever
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia -y
pip install transformers datasets pyserini huggingface_hub
# 安装 GPU 版 faiss
conda install faiss-gpu=1.8.0 -c pytorch -c nvidia -y
pip install uvicorn fastapi
Wiki配置文件#
我们使用Asearcher提供的本地检索文件,下载文件大约 50~60GB
conda activate retriever
save_path=/the/path/to/save
python examples/agent/searchr1/download.py --save_path $save_path
从huggingface上下载e5-base-v2 embedding模型,并生成index
bash examples/agent/tools/search_local_server_faiss/build_index.sh
将之前下载好的wiki文件路径和index路径等写入examples/agent/searchr1/launch_local_server.sh
#!/bin/bash
set -ex
WIKI2018_WORK_DIR=$save_path
index_file=$WIKI2018_WORK_DIR/e5.index/e5_Flat.index
corpus_file=$WIKI2018_WORK_DIR/wiki_corpus.jsonl
pages_file=$WIKI2018_WORK_DIR/wiki_webpages.jsonl
retriever_name=e5
retriever_path=path/to/intfloat/e5-base-v2
python3 ./local_retrieval_server.py --index_path $index_file \
--corpus_path $corpus_file \
--pages_path $pages_file \
--topk 3 \
--retriever_name $retriever_name \
--retriever_model $retriever_path \
--faiss_gpu --port 8000
运行launch_local_server.sh启动Local Wiki Server,等待直至输出server ip等信息,代表server启动完成
(Optional) 使用Qdrant作为Wiki Server#
我们也支持使用 qdrant 作为 wiki 服务器。如果你不打算使用 qdrant,可以直接跳到 训练 部分。
使用上一部分中提到的方式准备 Asearcher 提供的本地 wiki corpus 检索文件。
从 huggingface 上下载e5-base-v2 embedding 模型。
下载 qdrant 并按照以下步骤构建 qdrant collection。首先,创建一个文件夹并把下载好的 qdrant 二进制文件放入该文件夹中,方便后续存储 qdrant 程序及其构建的 collection 文件。
在 examples/agent/tools/search_local_server_qdrant/build_index_qdrant.sh 和 examples/agent/tools/search_local_server_qdrant/launch_local_server_qdrant.sh 中,根据之前下载的 wiki corpus, e5-base-v2 和 qdrant 路径更新 WIKI2018_DIR、 retriever_path 和 qdrant_path 的文件路径。
使用以下指令构建 qdrant wiki 服务器的 collection:
# 创建 qdrant 存放的文件夹
mkdir -p /path/to/qdrant
# 拷贝二进制执行文件
cp qdrant /path/to/qdrant
# 启动 qdrant server
/path/to/qdrant/qdrant &
# 构建 qdrant collection
bash examples/agent/tools/search_local_server_qdrant/build_index_qdrant.sh
运行 launch_local_server_qdrant.sh 启动 Local Qdrant Wiki Server ,等待直至输出 server ip 等信息,代表 server 启动完成
# 启动 qdrant server
/path/to/qdrant/qdrant &
# 启动基于 qdrant 的 wiki server
bash examples/agent/tools/search_local_server_qdrant/launch_local_server_qdrant.sh
Qdrant 默认使用 HNSW 图索引算法。关于 HNSW 图索引的优化,请参考 Qdrant 文档。
在8*H100上训练#
从huggingface上下载训练集
,并将路径写入 examples/agent/searchr1/config/train_qwen2.5.yaml:
data:
……
train_data_paths: ["/path/to/train.jsonl"]
修改 train_qwen2.5.yaml 中 rollout.model.model_path 的路径
rollout:
group_name: "RolloutGroup"
gpu_memory_utilization: 0.8
model:
model_path: /path/to/model/Qwen2.5-3B-Instruct
model_type: qwen2.5
如果使用 sampling_params.stop 来控制模型停止节省训练时间,detokenize应当设置为True
rollout:
……
distributed_executor_backend: mp # ray or mp
disable_log_stats: False
detokenize: True
由于 Search-R1 会re-tokenize模型输出, recompute_logprobs 应当设置为True
algorithm:
……
recompute_logprobs: True
shuffle_rollout: False
运行 bash examples/agent/searchr1/run_train.sh 启动训练。
评测#
运行以下命令将 Megatron checkpoint 转换为 HuggingFace model
CKPT_PATH_MG={your_output_dir}/{exp_name}/checkpoints/global_step_xxx/actor
CKPT_PATH_HF={path/to/save/huggingface/model}
CKPT_PATH_ORIGINAL_HF={path/to/model/Qwen2.5-3B-Instruct}
CKPT_PATH_MF="${CKPT_PATH_HF}_middle_file"
python -m rlinf.utils.ckpt_convertor.megatron_convertor.convert_mg_to_middle_file \
--load-path "${CKPT_PATH_MG}" \
--save-path "${CKPT_PATH_MF}" \
--model qwen_2.5_3b \
--tp-size 1 --ep-size 1 --pp-size 1 \
--te-ln-linear-qkv true --te-ln-linear-mlp_fc1 true \
--te-extra-state-check-none true --use-gpu-num 0 --process-num 16
python -m rlinf.utils.ckpt_convertor.megatron_convertor.convert_middle_file_to_hf \
--load-path "${CKPT_PATH_MF}" \
--save-path "${CKPT_PATH_HF}" \
--model qwen_2.5_3b \
--use-gpu-num 0 --process-num 16
rm -rf "${CKPT_PATH_MF}"
rm -f "${CKPT_PATH_HF}"/*.done
shopt -s extglob
cp "${CKPT_PATH_ORIGINAL_HF}"/!(*model.safetensors.index.json) "${CKPT_PATH_HF}"
将转换得到的huggingface
model路径填入 examples/agent/searchr1/config/eval_qwen2.5.yaml
rollout:
group_name: "RolloutGroup"
gpu_memory_utilization: 0.8
model:
model_path: /path/to/eval/model
model_type: qwen2.5
修改测试数据集路径
data:
……
val_data_paths: ["/path/to/eval.jsonl"]
运行 bash examples/agent/searchr1/run_eval.sh 启动测试。
可视化与结果#
下面展示 reward 曲线和训练时间曲线。
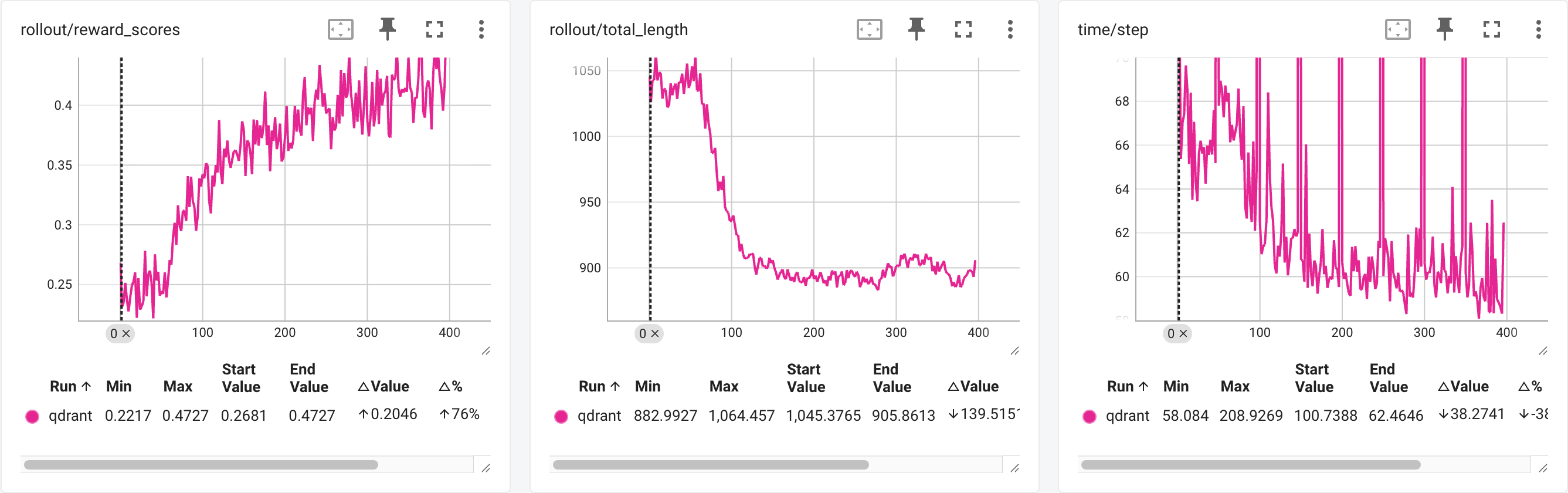
Qwen2.5-3B-Instruct in RLinf
相较于原版性能( response length 稳定后,单 step 133s),我们加速了 55%,同时 reward 曲线和 eval 结果保持一致。
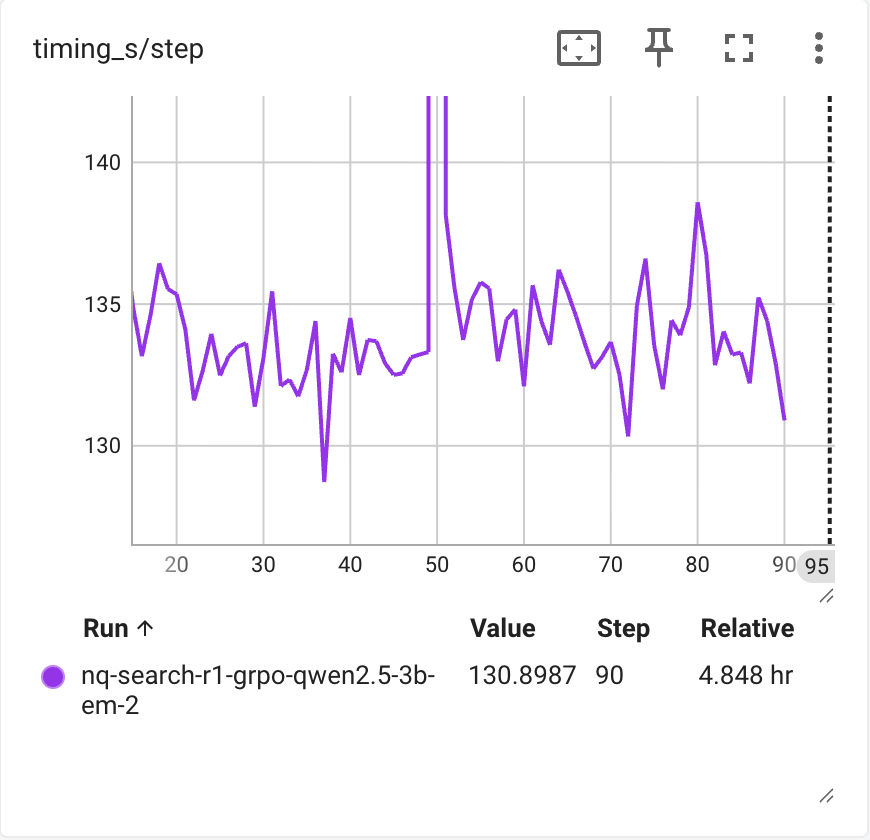
Qwen2.5-3B-Instruct in original implementation at PeterGriffinJin/Search-R1
References#
search-r1: PeterGriffinJin/Search-R1
Search-R1 & veRL-SGLang: zhaochenyang20/Awesome-ML-SYS-Tutorial
Asearcher: inclusionAI/ASearcher