使用 PPO 训练 Math 推理任务#
当你需要在 使用 GRPO 训练 Math 推理任务 中的同一数学推理任务上使用 actor-critic PPO 时,使用本配方。PPO 与 GRPO 共享大部分启动和数据设置,因此本页只列出 PPO 差异。
概述#
当你希望在与 GRPO 示例相同的数学推理任务上使用 actor-critic PPO 时,请使用本配方。
Qwen2.5-1.5B
PPO,使用 GAE 优势估计与 critic
AReaL-boba 数学推理数据
多 GPU Megatron 训练
数据集#
我们同样采用 boba 数据集,细节请参考 使用 GRPO 训练 Math 推理任务。
PPO 工作方式#
使用带 GAE advantage 和 critic 的标准 PPO(Proximal Policy Optimization)。算法细节见 PPO。
运行#
1. 配置文件
通用路径、集群和 runner 字段见 训练配置。推荐配置示例:
examples/reasoning/config/math/qwen2.5-1.5b-ppo-megatron.yaml
2. 启动命令
PPO 训练与 GRPO 训练的启动命令基本相同,也是使用 run_main_grpo_math.sh 作为入口脚本,RLinf 会通过 yaml 配置文件中是否存在 critic 相关配置以及 adv_type 的取值(PPO 通常使用 gae 作为优势函数)来自动判断是否使用 PPO 训练。
可视化与结果#
我们基于 Qwen2.5-1.5B-Instruct 模型使用 PPO 训练。橙色为 RLinf,蓝色为 VeRL;两者使用相同算法配置。通用指标含义见 训练指标。
由于 Qwen2.5-1.5B-Instruct 模型基础能力较弱,所以整体 reward 数值较低,但是随着训练的进行,reward 数值明显上升。
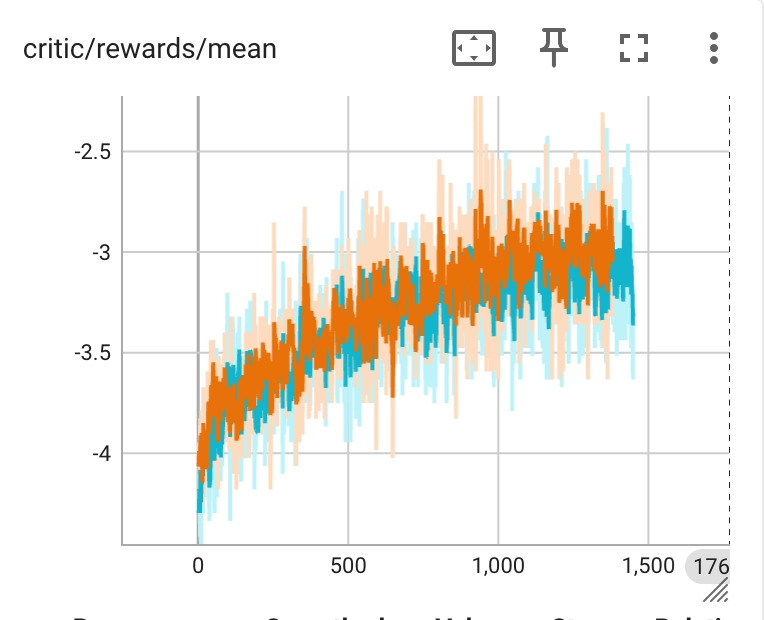
MATH 1.5B PPO