使用 GRPO 训练 Math 推理任务#
使用本配方在数学数据上用 GRPO 训练 Qwen 系列推理模型。相比监督微调,RL 鼓励模型探索更多样的推理路径,同时优化最终答案正确性。
概述#
使用本配方在数学数据上通过 GRPO 训练 Qwen 系列推理模型。
Qwen2.5-1.5B 与 Qwen2.5-7B
GRPO,使用 token-level loss 与 minibatch early-stop
AReaL-boba 数学推理数据
多节点 Megatron 训练
数据集#
我们使用 AReaL-boba-Data 数据集。 该数据集整合了 DeepScaleR、Open-Reasoner-Zero、Light-R1、DAPO、NuminaMath(AoPS/Olympiad 子集)和 ZebraLogic。 过于简单的问题会被过滤,以保证数据集质量和有效性。
一个训练样例如下:
{
"prompt": "<|User|>\nProblem description... Please reason step by step, and put your final answer within \\boxed{}.<|Assistant|><think>\n",
"task": "math",
"query_id": "xx",
"solutions": ["\\boxed{x}"]
}
备注
请确认数据集格式是按照上述结构配置。 否则,请仔细阅读下方的配置指南,使用 RLinf 适配您的数据集。
我们支持导入其他类型结构的数据集。 如需导入不同的数据集并作出特殊处理,您可根据需求调整配置。
Prompt key 和 answer key 配置
默认配置要求数据集使用
prompt和solutions键分别用于获取提示词信息和答案信息。但不同数据集可能使用不同的键名或结构,您可自定义配置以匹配数据集格式。 在配置 yaml 文件中修改
prompt_key和answer_key的值,使其指向数据集中对应的字段即可。比如说,如果您的数据集使用如下所示的
prompt和label作为键名,您需要设置:prompt_key: "prompt" answer_key: "label"
apply_chat_template 配置
部分数据集的提示词信息可能需要使用 tokenizer 中的 chat template 进行特殊处理。 若需此功能,需在配置中启用
apply_chat_template选项。apply_chat_template: true
比如说,如果您的数据集使用如下所示的特定结构对话消息,则需启用该选项以正确格式化提示词信息:
{ "prompt": [{"content": "<str>", "role": "<str>"},], "label": "<str>", }
启用该选项后,原始数据集将通过
tokenizer.apply_chat_template()方法处理,按照使用模型的 tokenizer 中对话模板对提示词信息进行格式化。 处理完成后,提示词信息将转换为字符串格式,用于模型输入。
GRPO 工作方式#
我们采用 GRPO(Group Relative Policy Optimization),并做了如下改进:
Token 级别的损失:不是在整个响应序列上平均损失,而是在 token 级别上平均(类似 DAPO)。 这样可以避免过长的回答主导训练,减少它们对梯度的影响。
小批次提前停止:如果一个 minibatch 中的重要性比率过大,则丢弃该批次,以稳定训练。
奖励函数:
最终 boxed/数值答案正确:+5
错误:-5
运行#
1. 关键参数配置
在启动前,检查配置文件。主要字段包括:
集群设置:
cluster.num_nodes(节点数)。路径:
runner.output_dir(保存训练日志与检查点的路径)、rollout.model.model_path(基础模型本地路径)、data.train_data_paths(训练数据路径)等。
2. 配置文件
推荐配置示例:
examples/reasoning/config/math/qwen2.5-1.5b-grpo-megatron.yamlexamples/reasoning/config/math/qwen2.5-7b-grpo-megatron.yaml
3. 启动命令
运行以下命令以启动 Ray 集群并开始训练:
cd /path_to_RLinf/ray_utils;
rm /path_to_RLinf/ray_utils/ray_head_ip.txt;
export TOKENIZERS_PARALLELISM=false
bash start_ray.sh;
if [ "$RANK" -eq 0 ]; then
bash check_ray.sh 128;
cd /path_to_RLinf;
bash examples/reasoning/run_main_grpo_math.sh qwen2.5-1.5b-grpo-megatron # 修改配置文件
else
if [ "$RANK" -eq 1 ]; then
sleep 3m
fi
sleep 10d
fi
sleep 10d
可视化与结果#
我们基于 DeepSeek-R1-Distill-Qwen 训练了 1.5B 和 7B 模型。
训练启动后,通过以下命令监控指标:
tensorboard --logdir ./logs --port 6006
通用指标含义见 训练指标。下面展示训练曲线。
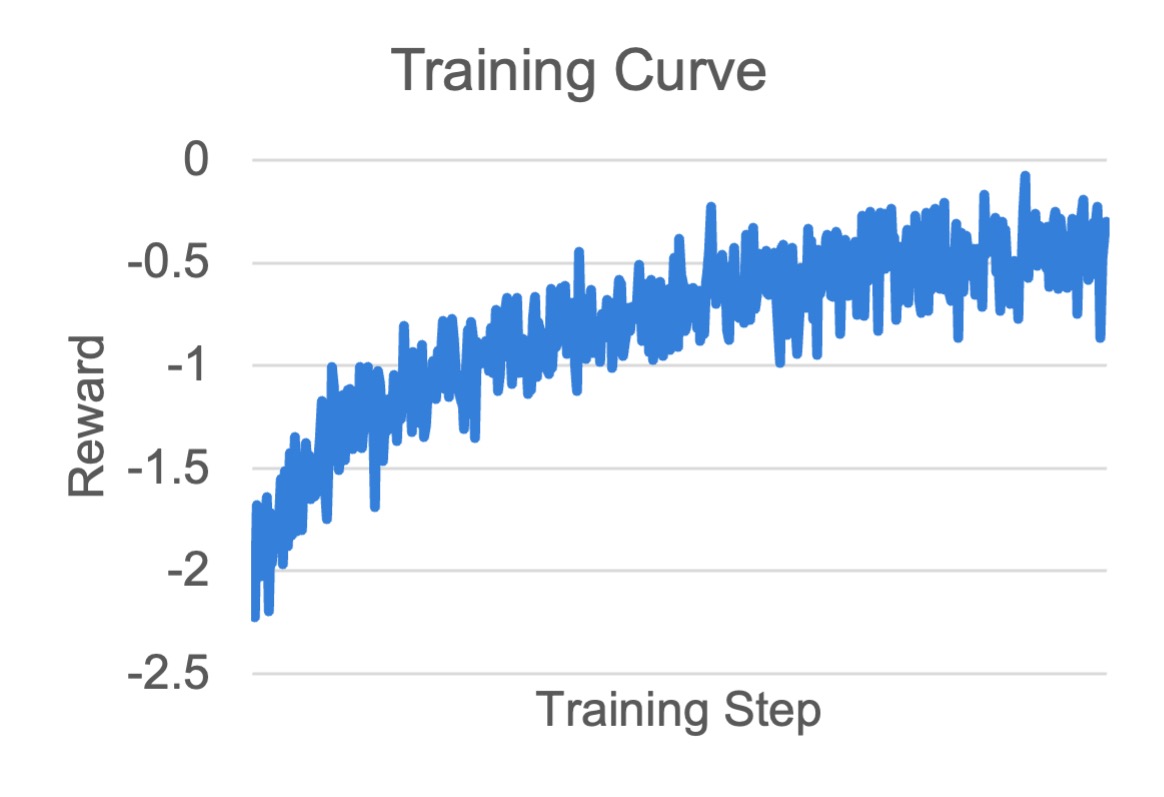
MATH 1.5B
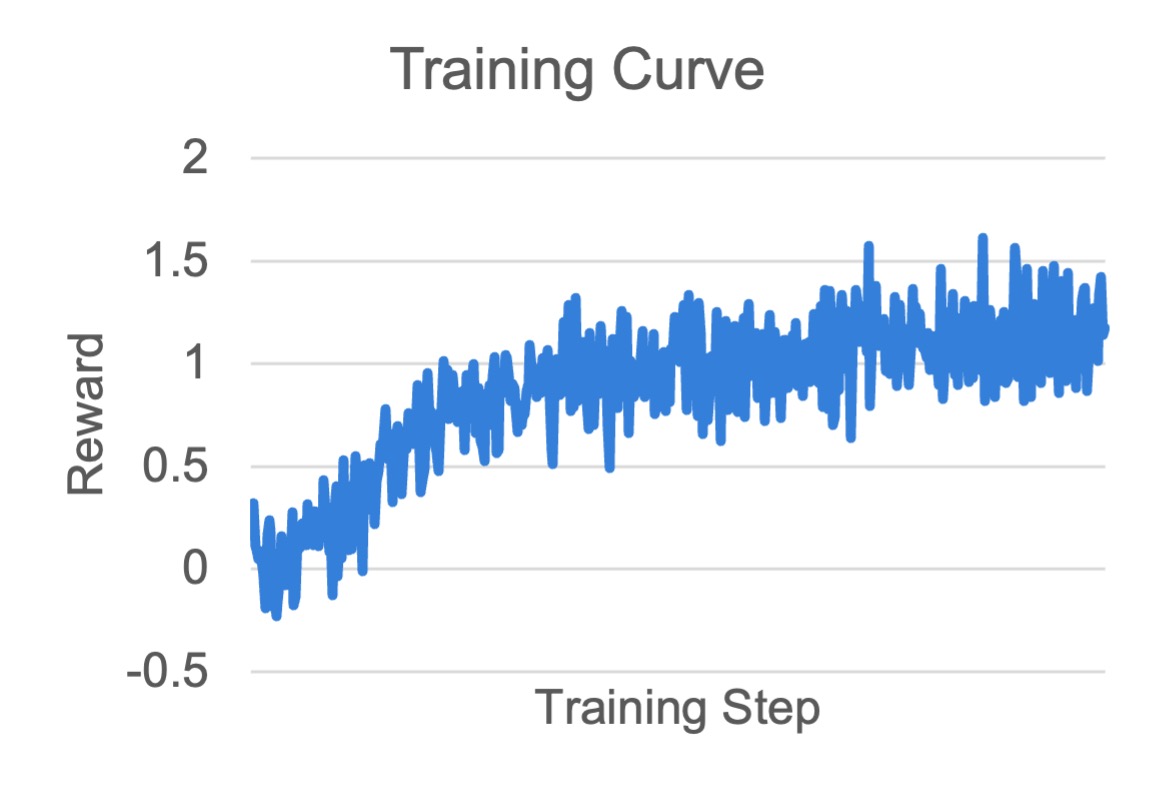
MATH 7B
最终性能#
我们提供了评估 工具包。
在 AIME24、AIME25 和 GPQA-diamond 上的评测结果表明,RLinf 达到了 SOTA 性能。
模型 |
AIME 24 |
AIME 25 |
GPQA-diamond |
平均值 |
|---|---|---|---|---|
28.33 |
24.90 |
27.45 |
26.89 |
|
37.80 |
30.42 |
32.11 |
33.44 |
|
40.41 |
30.93 |
27.54 |
32.96 |
|
40.73 |
31.56 |
28.10 |
33.46 |
|
AReaL-1.5B-retrain* |
44.42 |
34.27 |
33.81 |
37.50 |
43.65 |
32.49 |
35.00 |
37.05 |
|
48.44 |
35.63 |
38.46 |
40.84 |
* 我们使用默认配置对模型进行了 600 步重训。
模型 |
AIME 24 |
AIME 25 |
GPQA-diamond |
平均值 |
|---|---|---|---|---|
54.90 |
40.20 |
45.48 |
46.86 |
|
61.66 |
49.38 |
46.93 |
52.66 |
|
66.87 |
52.49 |
44.43 |
54.60 |
|
68.55 |
51.24 |
43.88 |
54.56 |
|
67.30 |
55.00 |
45.57 |
55.96 |
|
68.33 |
52.19 |
48.18 |
56.23 |
公开检查点#
我们在 Hugging Face 上发布了训练好的模型,供大家使用: